




系列导读
在前两篇文章中,我们分别从“算法框架与决策引擎”和“产品体验与价值衡量”两个角度出发,总结了超级个性化频道的技术脉络与产品要点。本文为“超级个性化与实时编排频道”系列终篇,本文将把视角上移到“生态”,讨论三个核心议题:可信赖的隐私与可解释性、对象化与模块化驱动的内容生产方式、以及人机协同与产业治理。我们的目标是给产品与工程团队提供一套可落地、可度量、可演进的实践路线图。
前文回顾:
千人千面进阶史:解码Netflix/Spotify背后的个性化算法战争
个性化频道的“最后一公里”:触点整合如何重塑用户内容消费范式
一、隐私与可解释性:构建可信赖的 AI
当个性化触达千人千面的深水区时,“准确推荐”不再是唯一目标,“可信赖推荐”才是产品可持续发展的分水岭。可信赖由三根支柱支撑:合规、透明、可控。
1.1 隐私增强技术(PETs)如何与推荐系统协同
隐私增强技术的核心主张是“数据可用而不可见”。在合规框架(GDPR、个人信息保护法等)下,平台需要在不暴露原始数据的前提下完成训练、推理与评估。工程上常见三件套:
· 差分隐私(DP):在统计查询或梯度更新中注入噪声,以降低单个样本被反推的风险。落地要点:为各类指标设计不同的隐私预算 ε,业务侧要接受“精度—隐私”的可调平衡;监控上以 AUC、NDCG、CTR 的变化区间作为验收门槛。
· 联邦学习(FL):让“模型去找数据”。下发基础模型到端侧,回收加密/加噪后的参数更新,在服务器端聚合。适用于跨设备与跨机构两种形态:前者强调设备异质性和不稳定在线;后者强调多组织协作与合规审计。
图-1 示例了传统集中式机器学习、分布式机器学习和联邦学习之间的区别。
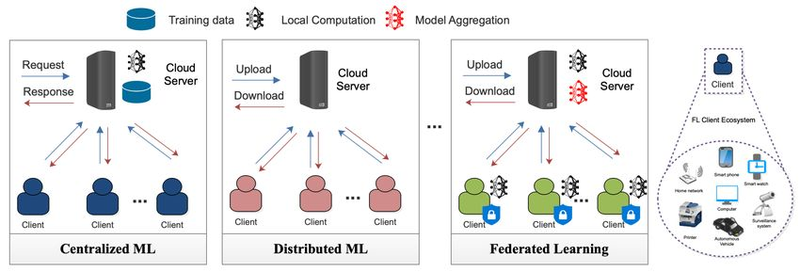
图-1 左图为传统中心化学习,所有原始数据都上传至服务器,中间为分布式学习,右边为联邦学习,数据保留在用户本地设备,模型在本地训练后,仅将更新(Update)上传。图片来源:Google AI*
· 安全多方计算(SMPC)/同态加密(HE):用于多主体联合建模或评估,典型于广告转化归因、反欺诈协作、跨域复合画像等场景。实践中常与 FL 组合,形成“端侧本地训练 + 机构侧安全聚合”的闭环。
备注: 上线前做三件事
(1)明确数据最小化清单(只采集实现目标所必需的数据);
(2)建立“可回溯的数据流图”(记录何时、何地、何人、何用途);
(3)引入“隐私预算看板”,把 ε 消耗纳入周指标,形成产品、法务、数据三方共识。
1.2 可解释性与用户控制权:从“默认黑箱”到“可对话白箱”
可解释性并不意味着把模型细节全部摊开,而是让用户与运营团队理解足够的理由:
· 面向用户的推荐理由:以“内容特征 + 行为触发”为主线,例如“因你喜欢××导演/类型”“与最近收藏的××在主题上相似”。在应用层支持一键隐藏某类理由或标签,避免“被贴脸画像”的不适。
· 面向运营/审核的解释工具:提供召回链路与特征贡献度的可视化,结合热力图、影响因子列表、反事实样本等方式定位问题。
· 公平与多样性治理:设置“曝光份额下限”“新增创作者扶持权重”等策略开关,并把多样性指标纳入日/周报表。
1.3 隐私工程落地清单(Privacy by Design)
· 数据分级分域:将用户标识、行为日志、内容元数据分级管理,跨域访问必须经由受控接口。
· 默认关闭敏感个性化:对涉及敏感特征的建模(如位置、健康、宗教等)默认关闭,要求显式同意与二次确认。
· “非个性化模式”随时可切换:提供无需画像即可运行的通用频道,满足法规与用户自由选择。
· 审计与追责:模型版本、训练数据分片、上线验证记录均需可回溯;关键策略变更需双人复核。
1.4 事实核查与风控边界
· 合规趋势:欧盟《数字服务法案》DSA要求大型平台提供推荐透明度与“非个性化”选项;国内《互联网信息服务算法推荐管理规定》明确了算法备案与重要变更报告要求。
· 常见误区:把“同意一次”等同于“永久授权”;忽视冷启动阶段的过度收集;在 A/B 测试中遗失隐私预算统计。
· 风控底线:任何时候不得用用户的隐私标签进行歧视性分发;对潜在伤害类内容建立“可解释的降权/屏蔽”机制,并保留复核通道。
二、内容生产启示:从“成品”到“可组合的积木”
超级个性化频道的优势,不仅在于呈现层的“千人千面”,更在于生产方式的重构:内容不再以一次性成片为终点,而是以“对象化、可重用”的数字资产为起点。
2.1 对象化媒体:颗粒化与模块化
BBC 率先提出 对象化媒体(Object‑Based Media, OBM):将节目拆解为可独立编排的对象(画面片段、音轨、字幕、元数据、互动控件等),在服务端或端侧按规则重组,从而实现更高的适配性与可达性。
图-2 详细展示了对象化媒体的制作过程。
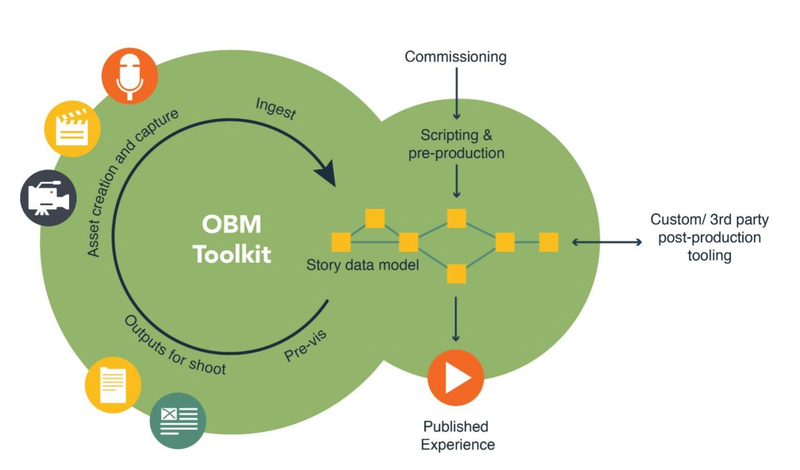
图-2 对象化媒体的制作流程
对象化带来三种直接收益:
1)重用与剪裁:同一素材可针对不同人群自动拼接“短平快”或“长深广”;
2)多版本共存:在语言、无障碍、分级上快速生成版本;
3)可度量:对象级别的曝光、完播、互动数据可反哺生产。

2.2 元数据驱动的动态编排
对象化的“骨架”是元数据。从基本标签(主题、人物、场景、节奏)到高阶特征(情绪、叙事结构、视觉风格),元数据的充分与准确决定了编排上限。工程上建议:
· 建立“标签本体”与“规则库”(如:节奏慢→弱化在午休时段的推荐权重);
· 结合自动识别(ASR、OCR、CV、情感分析)与人工校审形成闭环;
· 将“可解释的编排理由”连同对象 ID 写入日志,便于复盘。
2.3 生产流水线与团队角色重构
在内容供给侧,推荐驱动的生产与传统流程最大的不同,是数据与编辑同台:
· 数据策划:基于频道画像与缺口分析,提出对象化选题与拆分方案;
· 结构剪辑:以“可重组”为目标进行镜头与段落设计,输出对象图谱;
· 算法接口:通过模板/规则/约束,把“允许怎么拼”和“坚决不能怎么拼”固化到系统;
· 运营复核:上线前验证“推荐理由—对象组合—目标人群”的一致性。
备注: 实操模板 新增《对象化制作规划表》— 列出对象最小粒度、命名规范、元数据字段与校审流程; 引入“试播日”制度,对多个对象组合方案进行小流量验证。
2.4 多样性指标与生态健康
多样性并非“平均主义”,而是约束下的优化。建议引入:
· 内容类型覆盖率:在主流/小众品类之间设置配额与权重下限;
· 新作者冷启动包:给新人/小团队在前 N 次曝光中提供最低展示保障;
· 去重与新颖度:限制连续推送相似对象的频次;
· 生态观察面板:对“头部集中度、尾部活性、主题多样性、地区均衡”做月度监控与告警。
三、未来趋势:人机协同与生态共建
3.1 人机协同创作:从“辅助工具”到“共同作者”
生成式模型让“结构—素材—节奏”可以快速迭代,人类创作者将更多把精力放在选题、立意与价值把关上:
· AI 初稿 + 人类定稿:脚本、分镜、标题与封面由模型给出多版本,人类从“质量、价值、风险”三维筛选;
· 自动化后期:上字幕、转场、配乐与封面优化由批量脚本完成;
· 互动实验:基于对象化素材快速拼装 A/B 版本,对不同人群进行小流量分发,收敛到“最合适的版本”。
YouTube 的 Dream Screen 与一线创作工具的“智能剪片/字幕纠错/风格迁移”等能力,正在把上述流程变成日常。
3.2 开放生态与数据互联:从“孤岛平台”到“授权协同”
用户授权前提下,跨平台的语义画像与对象互用将成为可能:音乐平台的心情标签可提升视频平台的镜头节奏匹配;阅读平台的长文兴趣可帮助播客平台做主题串联。实现路径:
· 以数据契约定义字段、粒度、留存期与退出机制;
· 以隐私计算完成联邦训练与跨域评估;
· 以标准化 API 暴露对象查询与编排服务。
3.3 伦理与治理:从“平台自律”到“社会协同”
监管上,欧盟 DSA 强调透明与问责,国内《推荐算法管理规定》要求平台“向社会公开算法基本原理、目的与主要机制”,并提供“关闭个性化”入口。行业应主动把透明度报告制度化:披露重要指标、审核策略、申诉渠道与整改时效。
3.4 商业模式与变现:从“内容变现”到“数据与服务变现”
· 对象级授权:按对象或组合授权给合作方,形成“微版权”交易;
· 场景化广告与品牌内容:以对象为承载单元动态插入,遵循可解释与可关闭原则;
· 订阅 + 增值:在通用频道基础上提供“更可控、更可解释”的专业频道与数据面板服务。
3.5 标准与互操作性:从“内部规范”到“行业共识”
· 元数据标准化:对齐影视、新闻、体育等垂直领域的标签体系;
· 对象标识与引用:制定跨系统可解析的对象 ID 与依赖关系;
· 可移植的编排规则:将编排逻辑抽象为可共享的策略模板,便于跨平台复用。
3.6 研发路线图(12–18 个月建议)
1)上线 隐私预算看板 与 非个性化模式;
2)重构 对象化生产流水线,从 1–2 个栏目试点;
3)建立 多样性与公平性 指标体系并纳入周报;
4)开放 对象检索/编排 API 的内测,推动生态合作试点;
5)形成 透明度报告 与 算法变更审计 的常态机制。
结语
超级个性化频道的真正门槛,不在“是否能算得更准”,而在“是否能以可信赖的方式长期算得更准”。当隐私与可解释性内化为工程基线、当对象化生产成为组织常态、当生态协作打通数据与服务的边界,平台、创作者与用户三方的价值才会被稳定放大。技术与治理并行,才能把个性化带向更包容、更高质量的下一程。
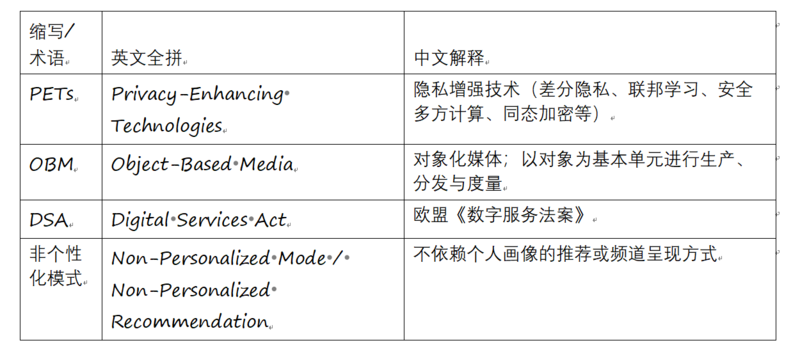
附录 A:名词与缩写
附录 B:实施清单(样例)
· 隐私:数据最小化清单、隐私预算仪表盘、端侧联邦学习灰度方案。
· 解释:推荐理由模板库、运营/审核解释视图、反事实样本库。
· 内容:对象化规划表、元数据本体与校审流程、自动识别模型集合。
· 生态:对象检索 API、编排规则模板、透明度报告周期与指标。
附录 C:案例与度量(示例)
案例一:资讯类频道的多样性提升
问题:频道在热点事件期间高度同质化,用户停留上升但订阅增长乏力。
动作:引入“主题多样性配额”,设定主线报道与延展阅读的曝光比例;对同一事件的不同视角采用对象化重组,新增“背景脉络卡”和“术语解释卡”。
结果:在不牺牲主线跟进速度的前提下,二跳率提升,投诉率下降,长期订阅转化有所改善。
指标:主题覆盖率、作者覆盖率、热词新颖度、被屏蔽词占比。
案例二:长视频栏目的人群细分回流
问题:主栏目完播率稳定但回访率下降。
动作:对长视频拆分为角色线、情节线、知识点线三种对象组合;引入“回看补丁”,为中断用户提供自动续看与关键情节回顾。
结果:弱关注用户的回访率显著提升,核心粉丝的时长保持稳定。
指标:分群完播率、回访间隔、对象级二次曝光率。
案例三:新作者冷启动
问题:冷启动阶段难以获取首批关注与互动。
动作:设置“新作者保护期”,在内容质量达标前提下给予最低曝光;对其对象化素材进行“风格聚类”,在相似风格频道中进行交叉曝光。
结果:冷启动时间缩短,内容生态更活跃。
指标:冷启动周期、首周关注数、跨频道触达数。
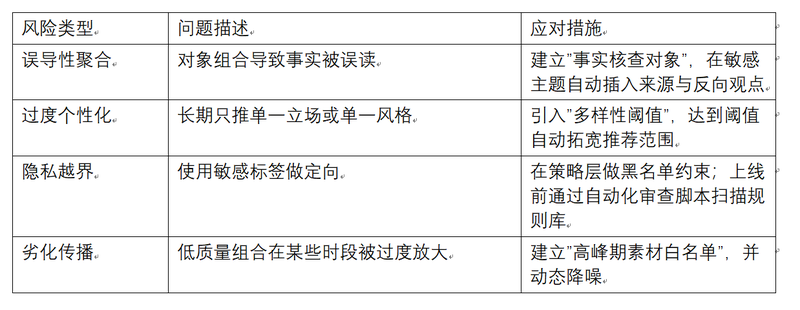
附录 D:风控场景剧本(样例)
实践问答(FAQ)
问:对象化一定会增加制作成本吗?
答:前期会有学习与流程改造成本,但在剪裁复用、快速多版本、长尾回收等方面能显著摊薄成本。建议以 1–2 个栏目试点,积累模板与规则后复制扩张。
问:如何把“解释性”做成用户价值而非负担?
答:控制颗粒度与场景化呈现。对普通用户只在关键位置展示简短理由,并提供“一键不再展示此类理由”;对专业用户则开放更细视图。
问:联邦学习会不会拖慢训练?
答:会引入通信与聚合开销。可通过端侧采样、分层聚合、压缩与自适应调度缓解;另外将“端上训练频率—收益”曲线纳入成本评估,避免盲目追求端上覆盖率。
问:如何定义可量化的“生态健康”?
答:建立“生态四象限”指标:头部集中度、尾部活性、主题多样性、地区均衡。再辅以“创作者生命周期”视角,跟踪从冷启动到成熟的转化漏斗。
参考资料与延伸阅读(官方/权威)
· 联邦学习:Google 官方介绍与案例 https://federated.withgoogle.com/
· 对象化媒体:BBC R&D 白皮书 WHP334(对象化生产工作流) https://downloads.bbc.co.uk/rd/pubs/whp/whp-pdf-files/WHP334.pdf
· 欧盟 DSA:欧盟委员会专题页 https://commission.europa.eu/strategy-and-policy/priorities-2019-2024/europe-fit-digital-age/digital-services-act_en
· Dream Screen:YouTube 官方博客与帮助文档 https://blog.youtube/news-and-events/made-on-youtube-2023/ https://support.google.com/youtube/answer/15260303
后记
把“更懂你”的体验长期做对,靠的不是一次灵感,而是体系化工程:权限可控、数据可回溯、内容可重组、生态可衡量。愿本系列能帮助团队在实践中形成共识:先把底层打稳,再让创意飞奔;先把风险收紧,再把体验做满。技术不断演进,但以用户为中心的边界与尊重不会改变。
推荐阅读:
责任编辑:凌美
24小时热文
流 • 视界










专栏文章更多
- [常话短说] 【重要】广电“壮士断腕”! 2025-12-11
- [常话短说] 【解局】广电降本增效“大有空间”?! 2025-12-10
- [勾正科技] 短剧榜单|电商,美妆行业持续发力,精品定制短剧推动品牌高声量 2025-12-09
- [探显家] CTV 广告从“注意力”转向“可验证的结果” 2025-12-09
- [常话短说] 【解局】这家广电网络公司宣布提前完成任务! 2025-12-09