




文章导读:本篇是基于开源大模型库快速实现AI应用系列教程之一,上一篇《利用开源Transformer模型实现主要的NLP文本相关应用》介绍了如何使用变换器模型的高级pipeline函数来处理不同的NLP任务。本文我们将从较高的层次探讨在生成式人工智能应用中各种被广泛采用的变换器模型的架构及其工作原理。变换器模型由Vaswani等人在论文《Attention is All You Need》中提出,已成为许多自然语言处理(NLP)领域最先进模型的基础。其架构设计用于处理顺序数据,使其成为文本翻译、摘要和情感分析等任务的理想选择。
通过本文的学习,您将全面了解Transformer模型的起源、基本结构、工作原理以及其在自然语言处理等领域的广泛应用。我们将深入探讨自注意力机制的核心原理、计算过程和多头自注意力的实现,帮助您理解其背后的智能逻辑。您将理解三种 Transformer 模型:纯编码器模型、纯解码器模型及编码器-解码器结合模型之间的区别和其应用场景。
关键词:Transformer(变换器)、注意力机制、大语言模型、纯编码器模型、纯解码器模型、编码器-解码器结合模型、模型预训练、模型微调。
前文回顾:
AI技术干货|大语言变换器模型的架构及其工作原理介绍(上篇)
3.纯编码器模型
3.1 简介
一个流行的仅包含编码器架构的例子是BERT(Bidirectional Encoder Representations from Transformers),它是这种模型中最受欢迎的。由Google在2018年提出的一种预训练语言模型,它在自然语言处理(NLP)领域取得了显著的成功,并刷新了多项任务的性能记录。BERT的主要创新之处在于其双向的上下文理解能力,这使得模型能够更准确地理解单词在句子中的含义。
我们通过对句子“欢迎来到北京”进行编码来介绍编码器的工作机制。首先,我们将这个中文句子分词为“欢迎 来到 北京”,并将这些词作为输入传递给编码器。编码器会为每个输入词检索其数值表示,也就是将“欢迎”、“来到”和“北京”转换为相应的数字序列或特征向量。
这些特征向量是经过BERT编码器处理的,每个向量都代表了通过编码器传递的每个单词的数值表示。这些向量的维度由模型的架构定义,对于基础BERT模型,维度是768。这些向量不仅包含了单词本身的信息,还融入了其上下文信息。例如,分配给单词“来到”的向量不仅仅是“来到”这个词的表示,它还考虑到了它周围的单词“欢迎”和“北京”,我们称之为“上下文”。因此,这个向量是一个上下文化的表示,它保存了该单词在文本中的“意义”。
这种上下文化的表示是通过自注意力机制实现的。自注意力机制能够关联到输入序列中的不同位置(或不同的单词),以计算该序列中每个单词的表示。这意味着一个单词的最终表示已经受到了序列中其他单词的影响,从而更好地捕捉了语义信息和上下文关系。
例如,在处理单词“来到”时,BERT编码器会考虑到其左侧的单词“欢迎”和右侧的单词“北京”,并综合这些上下文信息来生成“来到”的上下文化表示。这使得模型能够更准确地理解单词在句子中的含义和作用,从而在各种NLP任务中表现出色。
3.2 基本架构
BERT基于Transformer的编码器架构,由多层双向Transformer编码器堆叠而成。模型的输入是一串词嵌入,这些词嵌入会被送入每一层的Transformer编码器进行处理,最终输出的是每个单词的上下文化表示。
以下是BERT编码器内部模块的图示:
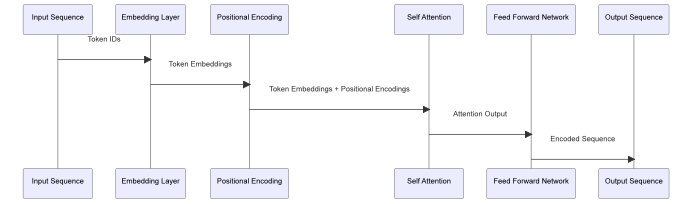
图 7 BERT 编码器模型的内部结构及相互间的关系
图中展示了BERT编码器的工作流程,包括以下模块:
1. 输入序列(Input Sequence):这是模型的输入,例如中文句子“欢迎来到北京”中的每个字或词作为一个输入token。
2. 嵌入层(Embedding Layer):该层将输入序列中的每个token转换为固定大小的向量(嵌入表示),这些向量包含了token的语义信息。
3. 位置编码(Positional Encoding):由于BERT模型本身不具有顺序感知能力,位置编码被加到嵌入表示中,以提供序列中每个元素的位置信息。
4. 自注意力机制(Self Attention):这一层使模型能够关注输入序列中的其他部分,从而更好地理解每个token的上下文信息。例如,在处理“北京”时,模型会考虑到“欢迎来到”这一上下文。
5. 前馈神经网络(Feed Forward Network):这是编码器的最后一层,它进一步处理自注意力层的输出,生成编码序列。
6. 输出序列(Output Sequence):这是编码器的输出,每个token都有一个对应的上下文化表示,这些表示将被用于下游任务。
这种模块化的设计使BERT能够有效地理解和处理自然语言,捕捉序列中的长距离依赖关系,并适应各种NLP任务。
3.3 预训练任务
BERT模型通过两种预训练任务来学习语言的结构和语义,这两种任务分别是Masked Language Model(MLM)和Next Sentence Prediction(NSP)。下面我们将详细介绍这两种任务,并结合具体的例子进行说明:
1. Masked Language Model(MLM):
· 任务描述:在输入序列中随机遮掩一些单词(通常为15%的单词),然后让模型预测被遮掩的单词。
· 例子:例如,我们有一个中文句子“今天天气真好,我们去公园吧。”在MLM任务中,我们可能会随机遮掩“天气”和“公园”,得到“今天[MASK]真好,我们去[MASK]吧。”模型的任务是预测这两个被遮掩的词。
· 目的:这种任务设计使得模型能够学习到单词之间的依赖关系和句子的内部结构,从而更好地理解语言语义和语法。
2. Next Sentence Prediction(NSP):
· 任务描述:给定两个句子,模型需要预测第二个句子是否是第一个句子的下一句。
· 例子:假设我们有两个句子:“今天天气真好。”和“我们去公园吧。”模型需要判断第二个句子是否是第一个句子的逻辑续句。在这个例子中,答案是肯定的。
· 目的:NSP任务有助于模型学习句子之间的逻辑关系和上下文信息,这对于理解段落和长文本尤为重要。
通过这两种预训练任务,BERT模型能够在大量无标注文本数据上进行训练,学习到丰富的语言知识,为后续的下游任务(如文本分类、问答系统等)提供强大的基础表示。
3.4双向上下文
BERT模型的一大特点是能够学习单词的双向上下文表示,这是通过利用Transformer的自注意力机制实现的。下面我们将详细解释这一特性,并结合具体的例子进行说明:
· 什么是双向上下文:
双向上下文表示意味着模型在学习某个单词的表示时,会同时考虑该单词在序列中的前面和后面的单词。这与传统的单向模型(只考虑前文或后文)形成对比,能够更全面地捕捉单词的语义信息。
· 如何实现:
BERT通过Transformer的自注意力机制实现双向上下文的学习。自注意力机制允许模型在编码单个单词时,权衡输入序列中的所有单词,从而生成一个包含整个序列信息的上下文化表示。
· 具体例子:
假设我们有一个中文句子:“小明喜欢吃苹果。”在学习“喜欢”这个词的表示时,BERT不仅会考虑“小明”这个前文信息,还会考虑“吃苹果”这个后文信息。这样,模型就能够更准确地理解“喜欢”这个词在当前句子中的具体含义。
· 与ELMo的区别:
ELMo虽然也能学习双向上下文,但它是通过分别学习两个单向LSTM(一个学习左到右的上下文,一个学习右到左的上下文)然后将两者结合起来实现的。而BERT通过自注意力机制,能够在一个统一的框架下直接学习双向上下文。
通过双向上下文的学习,BERT能够更为准确和全面地理解单词的语义,这使得它在各种自然语言处理任务中都表现出色。
3.5 应用与微调
编码器模型,如BERT,以其强大的能力和灵活性而著称,可以独立应用于各种自然语言处理任务。经过预训练后,BERT可以被微调用于各种NLP任务,如文本分类、命名实体识别、问答系统、序列分类和掩码语言建模(MLM)等。微调时,通常在BERT的基础上添加一层或多层任务相关的网络,并使用任务相关的数据进行训练。
编码器模型擅长提取序列中的有意义信息,并将其转化为向量形式,这些向量可以进一步由其他神经网络层进行处理和理解。
以掩码语言建模为例,这是一种预测序列中被隐藏单词的任务。我们可以用中文例子“我的 [MASK] 是金博士”来解释这一点。在这个例子中,“[MASK]”是被遮掩的部分,模型的任务是预测这个位置上最可能出现的词。由于BERT是一个双向模型,它会考虑“我的”和“是金博士”这两个部分的信息,来预测被遮掩的词。如果没有右边的词“是金博士”,模型很可能会难以准确预测出“[MASK]”的位置应该是“名字”。这是因为,仅凭左侧的“我的”这一信息,模型无法准确判断出句子的完整含义和上下文关系。
这种能力使编码器模型非常适合处理需要理解上下文和序列关系的任务,例如序列分类。情感分析就是一个典型的序列分类任务,模型需要根据输入序列的内容判断其情感倾向,例如是正面还是负面。即使两个序列在词汇上非常相似,甚至包含相同的词,但由于上下文的不同,它们的情感倾向可能会有很大的差异。编码器模型能够捕捉这些细微的差异,并做出准确的分类。
3.6 纯编码器模型的变种
BERT的成功催生了一系列的变种和扩展模型,如RoBERTa、DistilBERT、ALBERT等,这些模型在原有BERT的基础上进行了不同程度的改进和优化,以适应不同的应用场景和性能要求。

3.7 本章小结
总之,编码器模型,尤其是BERT,通过其强大的上下文理解能力和灵活性,在各种自然语言处理任务中展现出了卓越的性能,成为了该领域的重要基石。
4.解码器模型
VIP专享文章,请登录或扫描以下二维码查看

“码”上成为VIP会员
没有多余的门路、套路
只有简单的“值来值往”一路!
深度分析、政策解读、研究报告一应俱全
极致性价比,全年精彩内容不容错过!
更多福利,尽在VIP专享
24小时热文
流 • 视界










专栏文章更多
- [探显家] 好莱坞的“浮士德交易”:Paramount 和 Netflix 的竞购之战 2025-12-16
- [常话短说] 【解局】某广电向不良资产动刀 2025-12-16
- [常话短说] 【热评】广电做“错”了什么?! 2025-12-15
- [常话短说] 【重要】广电“壮士断腕”! 2025-12-11
- [常话短说] 【解局】广电降本增效“大有空间”?! 2025-12-10