




专题推荐:金博士AI技术干货分享
相关阅读:AI技术干货|词嵌入技术详解系列之基础技术(上篇)
引言
词嵌入是生成式人工智能中的一项关键技术,是一种将词语或短语从词汇表(可能包含数千或数百万个词语)映射到向量的实数空间的技术。这些嵌入捕获了词语之间的相似性,因此相似的词语会被映射到相近的点。词嵌入可以分为两类:基于计数的方法和预测方法。基于计数的方法计算某词语与其邻近词语在大型文本语料库中共同出现的频率及其他统计量,然后将这些统计量映射到一个小的、密集的向量。预测方法则试图直接从某词语的邻近词语预测该词语,预测模型的参数即为词嵌入。
词嵌入在自然语言处理(NLP)中有许多具体的应用,包括但不限于以下几个方面:
1. 情感分析:词嵌入可以帮助机器理解文本的情感,例如判断用户评论是正面的还是负面的。
2. 文本分类:词嵌入可以用于新闻分类、垃圾邮件检测等任务,帮助机器理解文本的主题并进行分类。
3. 命名实体识别:通过词嵌入,机器可以识别出文本中的特定实体,如人名、地名、组织名等。
4. 机器翻译:词嵌入在机器翻译中也起着关键作用,帮助机器理解源语言,并将其准确地翻译成目标语言。
5. 语义搜索:词嵌入可以用于搜索引擎,提高搜索结果的相关性,使搜索结果更符合用户的查询意图。
6. 问答系统:词嵌入可以帮助问答系统理解用户的问题,并提供准确的答案。
7. 语音识别:词嵌入可以帮助语音识别系统理解用户的语音指令,并执行相应的操作。
8. 聊天机器人:词嵌入可以帮助聊天机器人理解用户的输入,并生成自然、相关的回复。
总的来说,词嵌入是许多自然语言处理任务的基础,它使机器能够理解和处理人类语言,从而实现更高级的功能。
Skip-gram 跳字模型详解
N-gram 介绍
N-gram模型是一种基于统计语言模型,它的基本思想是将文本里面的内容按照字节进行大小为n的滑动窗口操作,形成了长度是n的字节片段序列。每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一项称为维度。维度的数值就是gram在文本中出现的频度。
以下是一些具体的例子:
1. Unigram模型:1-gram模型是最简单的N-gram模型,其中每个词都是独立的。例如,考虑句子"我爱吃苹果"。Unigram模型将句子视为单独的词的集合,即{"我","爱","吃","苹果"}。这种模型通常用于词频统计等任务。
2. Bigram模型:2-gram模型考虑句子中的两个连续词的关系。例如,对于同样的句子"我爱吃苹果",Bigram模型将生成{"我爱","爱吃","吃苹果"}。这种模型能够捕捉到一些语言中的短语和常见词组。
3. Trigram模型:3-gram模型进一步考虑句子中的三个连续词的关系。例如,对于句子"我非常爱吃苹果",Trigram模型将生成{"我非常爱","非常爱吃","爱吃苹果"}。这种模型能够捕捉到更复杂的语言模式。
N-gram模型在许多自然语言处理任务中都有应用,包括文本分类、情感分析、语音识别和机器翻译等。然而,它也有一些局限性,例如,它无法捕捉到长距离的依赖关系(即,当一个词的出现依赖于距离它很远的另一个词时)。为了解决这个问题,研究人员已经提出了许多其他类型的语言模型,如循环神经网络(RNN)和变换器模型。
在实际应用中,选择使用哪种N-gram模型取决于具体的任务和数据。一般来说,随着N的增大,模型能够捕捉到更多的上下文信息,但同时也会增加模型的复杂性和计算成本。基于n-gram的应用包括:
· 文本分类和情感分析:n-gram模型可以用于提取文本特征,这些特征可以用于训练分类器,如朴素贝叶斯分类器,以进行文本分类或情感分析。例如,bigram和trigram可以捕获否定短语(如"不好")的情感。
· 语音识别:在语音识别中,n-gram模型用于语言模型,帮助系统理解可能的词序列,从而提高识别准确性。
· 机器翻译:在统计机器翻译中,n-gram模型用于评估生成的翻译的流畅性和自然性。
· 拼写检查和自动纠错:n-gram模型可以用于预测给定上下文中最可能的下一个词,这在拼写检查和自动纠错中非常有用。
· 搜索引擎:搜索引擎使用n-gram模型来理解和索引网页内容,以及处理用户查询。
在使用基于n-gram的应用时,研发者需要考虑如下的问题:
· 数据稀疏问题:随着n的增大,n-gram模型会遇到数据稀疏问题。也就是说,许多n-gram可能只在训练数据中出现一次,这使得模型难以泛化到未见过的n-gram。
· 长距离依赖:n-gram模型难以处理长距离的词依赖。例如,在句子"我昨天在公园遇到了一个老朋友,他现在在纽约工作"中,"他"和"老朋友"之间有长距离的依赖关系,这在n-gram模型中难以捕捉。
· 计算和存储需求:存储大量n-gram需要大量的内存,特别是对于大的n值。此外,计算n-gram概率也需要大量的计算资源。
· 模型选择:选择合适的n值是一个挑战。较小的n值可能无法捕捉到足够的上下文信息,而较大的n值可能导致数据稀疏问题。
为了解决这些问题,研究人员已经开发出了更复杂的语言模型,如基于神经网络的模型,例如Word2Vec,GloVe和BERT等。这些模型可以捕捉到更复杂的词关系,并且可以更好地处理数据稀疏和长距离依赖问题。
skip-gram 介绍
n-gram和skip-gram是两种处理和理解文本数据的技术,它们都是自然语言处理(NLP)中的重要工具。n-gram和skip-gram都是处理序列数据的方法,但它们的目标和应用有所不同。n-gram更关注词序列的概率,而skip-gram更关注通过一个词预测其上下文。在某种程度上,skip-gram可以被看作是n-gram的一种扩展,它不仅考虑了紧邻的词,还考虑了跳过一些词的情况。这使得skip-gram能够捕捉到更远距离的词间关系。
例如,对于句子"The quick brown fox jumps over the lazy dog",在bigram模型中,"fox"和"over"之间的关系可能会被忽略,因为它们不是紧邻的。但在skip-gram模型中,只要"over"在"fox"的窗口范围内,就可以被考虑在内。
Skip-gram是一种在自然语言处理和特别是在词嵌入模型中常用的技术。它是Word2Vec模型的一部分,由Google的研究人员于2013年提出。Skip-gram的主要目标是通过学习词的上下文来生成词的高质量向量表示。
Skip-gram模型的工作原理与CBOW模型恰好相反。在CBOW模型中,我们根据上下文词来预测目标词(中心词)。而在Skip-gram模型中,我们根据目标词(中心词)来预测上下文词。
例如,假设我们有一个句子"The cat sat on the mat",我们选择"sat"作为目标词,如果我们选择上下文窗口大小为2,那么我们的上下文词就是["The", "cat", "on", "the"]。在Skip-gram模型中,我们的任务就是根据"sat"来预测这些上下文词。
Skip-gram模型的训练过程涉及到优化一个目标函数,这个目标函数基于最大化给定目标词预测上下文词的概率。这个过程通常涉及到大量的计算,因为它需要更新模型的所有参数以最小化预测错误。然而,有一些优化技术,如负采样(Negative Sampling)和层次化softmax(Hierarchical Softmax),可以大大提高训练的效率。
Skip-gram模型的一个主要优点是它能够有效地处理罕见的单词。因为Skip-gram模型是根据目标词来预测上下文词,所以即使一个单词在训练数据中出现的次数很少,Skip-gram模型也能够学习到这个单词的词向量。
然而,Skip-gram模型的一个主要缺点是它的训练过程比CBOW模型更加复杂和耗时。这是因为Skip-gram模型需要对每个目标词的每个上下文词进行预测,这需要大量的计算资源。
总的来说,Skip-gram模型是一种强大的工具,可以用于学习词的向量表示,尤其是在处理包含罕见单词的大型数据集时。
Skip-gram工作机理详解
以下是 Skip-gram 的工作流程图:
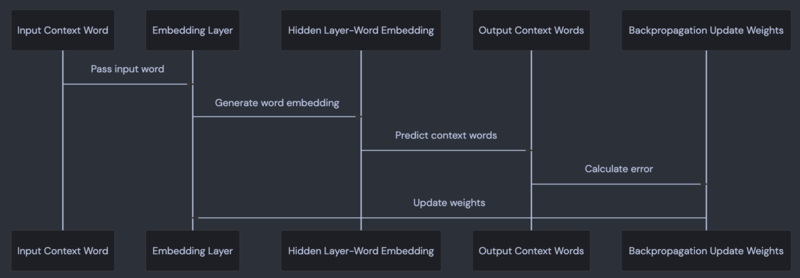
图 6 Skip-gram 的工作过程
Skip-gram模型的工作可以分为如下五个环节或步骤,下面我们详细加以说明。
第一个环节 - 输入上下文
在 Skip-gram 模型中,第一个环节是接收输入词。这个输入词通常是我们想要学习其上下文关系的目标词。例如,如果我们有句子 "The cat sat on the mat.",我们可能会选择 "sat" 作为输入词。
在 Skip-gram 模型中,输入词被表示为一个 one-hot 向量。这是一个长度等于词汇表大小的向量,向量中的元素全为 0,除了表示输入词的索引位置的元素为 1。例如,如果我们的词汇表是 ["the", "cat", "sat", "on", "mat"],那么 "sat" 的 one-hot 向量就是 [0, 0, 1, 0, 0]。
这个 one-hot 向量会被送入模型,通过嵌入层转换为一个密集的词嵌入向量,这个向量捕捉了输入词的语义信息。这就是 Skip-gram 模型的输入环节。
第二个环节 - 嵌入层
在 Skip-gram 模型中,第二个环节是嵌入层。这个环节的任务是将输入的 one-hot 向量转换为一个密集的词嵌入向量。这个词嵌入向量是通过学习得到的,它能捕捉到词的语义信息。
例如,如果我们的输入词是 "sat",它的 one-hot 向量是 [0, 0, 1, 0, 0]。在嵌入层,这个 one-hot 向量会被映射到一个更小的 (相对于整个单词库大小而言),通常是几百维的向量。这个向量是密集的,也就是说,它的每个元素都是一个实数值,而不仅仅是 0 或 1。这个向量就是 "sat" 的词嵌入。
这个词嵌入是通过模型训练学习得到的。在训练过程中,模型会调整词嵌入的值,使得相似的词有相似的词嵌入。例如,"sat" 和 "sit" 在某种程度上是相似的(它们都是坐的意思),所以它们的词嵌入应该很接近。
第三个环节 - 隐藏层词嵌入
在 Skip-gram 模型中,第三个环节是隐藏层,也被称为词嵌入层。在这个环节,我们已经得到了输入词的词嵌入向量,这个向量包含了输入词的语义信息。
例如,我们的输入词是 "cat",在嵌入层,我们得到了 "cat" 的词嵌入向量,比如 [0.1, 0.3, -0.2, ...]。这个向量是一个密集向量,它的每个元素都是一个实数值。
在隐藏层,这个词嵌入向量不会进行任何处理,它会直接被送到下一个环节。这是因为在 Skip-gram 模型中,我们的目标是根据输入词预测它的上下文词,所以我们需要保留输入词的所有语义信息,而这些信息都包含在词嵌入向量中。
这个词嵌入向量会被送到下一个环节,用于预测输入词的上下文词。
第四个环节 - 输出上下文词
在 Skip-gram 模型中,第四个环节是输出上下文词。在这个环节,我们使用输入词的词嵌入向量来预测它的上下文词。
例如,我们的输入词是 "cat",我们需要预测它的上下文词,比如 "a", "black", "on", "the", "mat"。在这个环节,我们会对每个可能的上下文词计算一个分数,这个分数表示了这个词是输入词的上下文词的可能性。
这个分数是通过将输入词的词嵌入向量和上下文词的词嵌入向量进行点积运算,然后通过 softmax 函数转换为概率得到的。例如,如果 "black" 的词嵌入向量和 "cat" 的词嵌入向量的点积结果是 0.2,那么经过 softmax 函数转换后,我们得到 "black" 是 "cat" 的上下文词的概率是 0.2。
这个环节的输出是所有可能的上下文词及其对应的概率,这些概率之和为 1。这个输出会被送到下一个环节,用于计算损失函数和进行反向传播。
第五个环节- 反向传播更新权重
在 Skip-gram 模型中,第五个环节是反向传播更新权重。在这个环节,我们根据模型的预测结果和实际的上下文词来更新模型的参数,以便提高模型的预测准确性。
例如,我们的输入词是 "cat",实际的上下文词是 "black",但模型预测的上下文词是 "white"。这时,我们需要更新模型的参数,使得模型在下次遇到 "cat" 时,能更可能地预测出 "black"。
更新参数的方法是通过计算损失函数的梯度来实现的。损失函数衡量的是模型预测的上下文词和实际的上下文词之间的差距。在这个例子中,损失函数的值可能是 "black" 和 "white" 的词嵌入向量之间的距离。
我们首先计算损失函数关于模型参数的梯度,然后按照梯度的反方向更新参数。这个过程叫做梯度下降。
这个环节的输出是更新后的模型参数,包括词嵌入向量和其他参数。这些参数会被用于下一次的预测。
Skip-gram的优劣势分析
VIP专享文章,请登录或扫描以下二维码查看

“码”上成为VIP会员
没有多余的门路、套路
只有简单的“值来值往”一路!
深度分析、政策解读、研究报告一应俱全
极致性价比,全年精彩内容不容错过!
更多福利,尽在VIP专享
24小时热文
流 • 视界










专栏文章更多
- [常话短说] 【热评】广电做“错”了什么?! 2025-12-15
- [常话短说] 【重要】广电“壮士断腕”! 2025-12-11
- [常话短说] 【解局】广电降本增效“大有空间”?! 2025-12-10
- [勾正科技] 短剧榜单|电商,美妆行业持续发力,精品定制短剧推动品牌高声量 2025-12-09
- [探显家] CTV 广告从“注意力”转向“可验证的结果” 2025-12-09