




专题推荐:金博士AI技术干货分享
相关阅读:AI技术干货|词嵌入技术详解系列之基础技术(上篇)
引言
词嵌入是生成式人工智能中的一项关键技术,是一种将词语或短语从词汇表(可能包含数千或数百万个词语)映射到向量的实数空间的技术。这些嵌入捕获了词语之间的相似性,因此相似的词语会被映射到相近的点。词嵌入可以分为两类:基于计数的方法和预测方法。基于计数的方法计算某词语与其邻近词语在大型文本语料库中共同出现的频率及其他统计量,然后将这些统计量映射到一个小的、密集的向量。预测方法则试图直接从某词语的邻近词语预测该词语,预测模型的参数即为词嵌入。
词嵌入在自然语言处理(NLP)中有许多具体的应用,包括但不限于以下几个方面:
1. 情感分析:词嵌入可以帮助机器理解文本的情感,例如判断用户评论是正面的还是负面的。
2. 文本分类:词嵌入可以用于新闻分类、垃圾邮件检测等任务,帮助机器理解文本的主题并进行分类。
3. 命名实体识别:通过词嵌入,机器可以识别出文本中的特定实体,如人名、地名、组织名等。
4. 机器翻译:词嵌入在机器翻译中也起着关键作用,帮助机器理解源语言,并将其准确地翻译成目标语言。
5. 语义搜索:词嵌入可以用于搜索引擎,提高搜索结果的相关性,使搜索结果更符合用户的查询意图。
6. 问答系统:词嵌入可以帮助问答系统理解用户的问题,并提供准确的答案。
7. 语音识别:词嵌入可以帮助语音识别系统理解用户的语音指令,并执行相应的操作。
8. 聊天机器人:词嵌入可以帮助聊天机器人理解用户的输入,并生成自然、相关的回复。
总的来说,词嵌入是许多自然语言处理任务的基础,它使机器能够理解和处理人类语言,从而实现更高级的功能。
连续词袋模型(CBOW)详解
词袋模型 (BOW)
词袋模型是一种流行的词嵌入技术,在这种技术中,向量中的每个值代表文档/句子中的词的计数。换句话说,它从文本中提取特征。我们也称之为向量化。
要开始创建词袋模型,可以按照以下步骤进行:
· 首先,我们需要将文本分割成句子。
· 接下来,将第一步中的句子进一步分割成单词。
· 消除任何停用词或标点符号。
· 然后,将所有单词转换为小写(对于纯中文不存在该步骤)。
· 最后,创建单词的频率分布图。
我们将在下面的连续词袋选择中讨论词袋模型的具体例子。
连续词袋模型CBOW
连续词袋模型(Continuous Bag of Words,CBOW)是 Word2Vec 中的一种模型,它的目标是根据上下文词汇预测目标词汇。CBOW 模型的名称来源于它将上下文视为一个词袋,即不考虑词汇的顺序。
CBOW 模型的工作方式可以通过以下步骤进行描述:
1. 输入和输出:CBOW 模型的输入是目标词汇的上下文词汇,输出是目标词汇本身。例如,在句子 "The cat sat on the mat." 中,如果我们选择 "sat" 作为目标词汇,那么输入就是 "The", "cat", "on", "the", "mat",输出就是 "sat"。
2. 词向量:在 CBOW 模型中,每个词汇都有一个对应的词向量,这个词向量是模型训练过程中学习到的。词向量的维度远小于词汇表的大小,这使得 CBOW 模型能够有效地处理大规模的文本数据。
3. 预测:CBOW 模型通过计算输入词汇的词向量的平均值,然后使用这个平均值去预测目标词汇。预测的方式通常是计算平均词向量与每个可能的目标词汇的词向量之间的相似度,然后选择相似度最高的词汇作为预测结果。
4. 训练:CBOW 模型的训练目标是使模型的预测结果尽可能接近真实的目标词汇。这通常通过最小化预测错误(例如,使用交叉熵损失函数)来实现。训练过程中,模型会不断调整词向量,使得相似的词汇(即在相似上下文中出现的词汇)有相似的词向量。
通过这种方式,CBOW 模型能够捕捉到词汇的语义和语法关系,例如,"cat" 和 "dog" 都可能出现在 "_ is a pet" 的空格中,因此它们的词向量可能会很接近。
下面是 CBOW 模型的工作流程图:
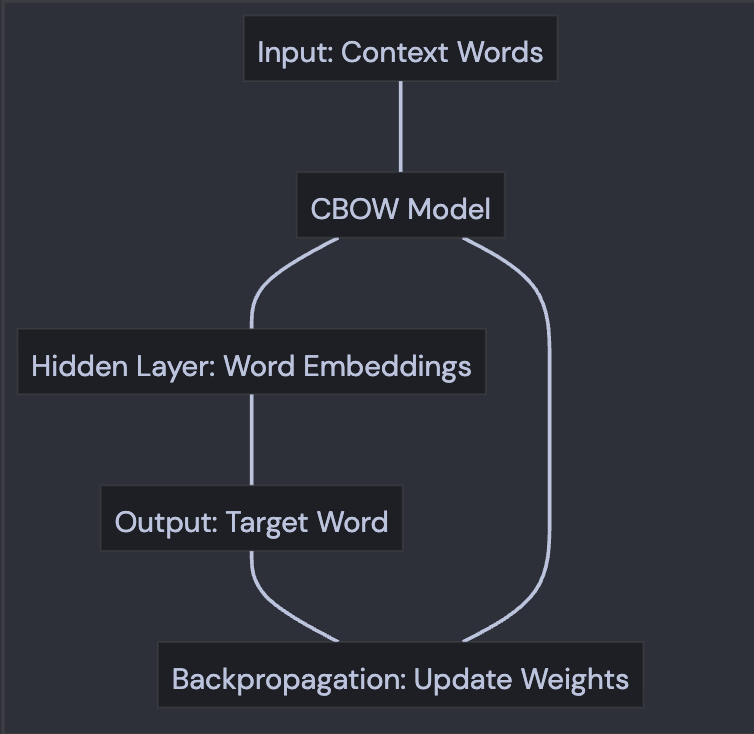
图 5 CBOW 的工作流程图
下面是对上图中每个环节的说明。
CBOW 工作机理详解
CBOW 模型的工作可以分为如下五个环节或步骤,下面我们详细加以说明。
第一个环节 - 输入上下文
在 Word2Vec 的 CBOW 模型中,输入是目标词的上下文词。上下文词是指在目标词周围的词。例如,在句子 "the cat sat on the mat" 中,如果我们选择 "sat" 作为目标词,那么 "the", "cat", "on", "the", "mat" 就是它的上下文词。如果我们选择上下文窗口大小为 2,那么我们的输入可能是 "the", "cat", "on", "the"。
在 CBOW 模型中,上下文词被编码为一个独热向量。独热向量是一个长度等于词汇表大小的向量,其中只有一个元素是 1(表示该词),其余元素都是 0。例如,如果我们的词汇表是 ["the", "cat", "sat", "on", "mat"],那么 "cat" 的独热向量就是 [0, 1, 0, 0, 0]。
然后,这些独热向量被送入神经网络,通过与词嵌入矩阵相乘,得到每个上下文词的词嵌入。这些词嵌入然后被平均(或求和),得到一个表示整个上下文的向量。这个向量就是 CBOW 模型的输入。
这个过程的目的是将上下文词的信息编码到一个固定长度的向量中,这个向量可以被神经网络处理,用来预测目标词。
第二个环节 - CBOW 模型
在 Word2Vec 的 CBOW 模型中,我们使用上下文词(context words)来预测目标词(target word)。上下文词是目标词周围的词,目标词是我们试图预测的词。
例如,考虑句子 "the cat sat on the mat"。如果我们选择 "sat" 作为目标词,并选择一个上下文窗口大小为 2,那么我们的上下文词就是 "the", "cat", "on", "the"。这些上下文词作为输入,被送入模型,目标词 "sat" 是我们试图预测的输出。
在 CBOW 模型中,每个输入词首先会被转换为一个词嵌入向量。这个词嵌入向量是一个固定大小的实数向量,它捕捉了词的语义信息。例如,"cat" 和 "dog" 这两个词可能有相似的词嵌入,因为它们都是动物和宠物。
这些词嵌入向量然后被平均(或者以其他方式组合),形成一个新的向量,这个向量被送入隐藏层。这个新的向量捕捉了上下文词的整体语义信息,它将被用来预测目标词。
通过这种方式,CBOW 模型可以从上下文中学习到词的语义信息。
第三个环节 - 隐藏层词嵌入
在 Word2Vec 中,隐藏层的主要作用是存储词嵌入(也称为词向量)。词嵌入是一种将词语转化为数值向量的技术,这些向量能够捕捉到词语的语义信息,例如词语之间的相似性和词语之间的关系。
仍然以句子 "the cat sat on the mat"为例,我们选择 "sat" 作为目标词,上下文窗口大小为 2,那么我们的输入就是 "the", "cat", "on", "the"。在隐藏层,每个输入词都会被映射到一个向量,例如,"cat" 这个词可能会被映射到一个如下的向量:
[0.2, -0.3, 0.8, -1.2, 0.5, ...]
这个向量就是 "cat" 这个词的词嵌入。通过这个词嵌入,我们可以捕捉到 "cat" 这个词的语义信息。例如,我们会发现 "cat" 和 "dog" 的词嵌入在向量空间中很接近,这是因为 "cat" 和 "dog" 在语义上是相似的。
隐藏层的输出(也就是所有输入词的词嵌入)然后会被平均,生成一个新的向量,这个向量会被送到输出层,用来预测目标词。
第四个环节 - 输出目标词
VIP专享文章,请登录或扫描以下二维码查看

“码”上成为VIP会员
没有多余的门路、套路
只有简单的“值来值往”一路!
深度分析、政策解读、研究报告一应俱全
极致性价比,全年精彩内容不容错过!
更多福利,尽在VIP专享
24小时热文
流 • 视界










专栏文章更多
- [探显家] 好莱坞的“浮士德交易”:Paramount 和 Netflix 的竞购之战 2025-12-16
- [常话短说] 【解局】某广电向不良资产动刀 2025-12-16
- [常话短说] 【热评】广电做“错”了什么?! 2025-12-15
- [常话短说] 【重要】广电“壮士断腕”! 2025-12-11
- [常话短说] 【解局】广电降本增效“大有空间”?! 2025-12-10