




自流媒体商业模式成行以来,十多年期间其收入结构并没有太大变化:订阅、广告、交易点播、渠道分销,以及增值合作。如果我们进一步抽象,就会发现它们不过是两种方式的变种:一种是卖内容,另一种是卖注意力。前者靠内容本身让用户付费,后者靠内容吸引的注意力让广告主付费。无论平台大小、内容长短,这个规律从未改变。
但规律之所以值得记录,是因为它总有被打破的时候。
一家小众垂类流媒体的营收“范式转移”
今年在 Parks Associates 的 Future of Video 大会上,Needham & Company 的资深分析师 Laura Martin 给出了一个具有代表性的样本:一家小众垂类 OTT 流媒体平台,其收入结构正在发生质变——接近一半的营收来自内容许可,而这些内容的主要买方不再是传统媒体渠道,而是模型公司,用于训练 LLMs(大模型)。

这件事之所以值得注意,并不是因为“多了一个收入来源”,而是因为它揭示了流媒体内容在价值链条中的位置正在发生迁移。
CuriosityStream,作为一家规模并不算大的小众流流媒体,在相对低调的操作下,已经在视频行业开启了一场“范式转移”:它将自有、完整版权的内容授权给了 LLM(大型语言模型)运营方,用于 AI(人工智能)训练。其 2025 年 Q3 财报揭示,内容许可收入达 870 万美元,占总营收 1840 万美元的 47.3%。这一收入与用户观看行为完全无关,却能显著改善毛利结构,甚至在未来具备可持续属性。
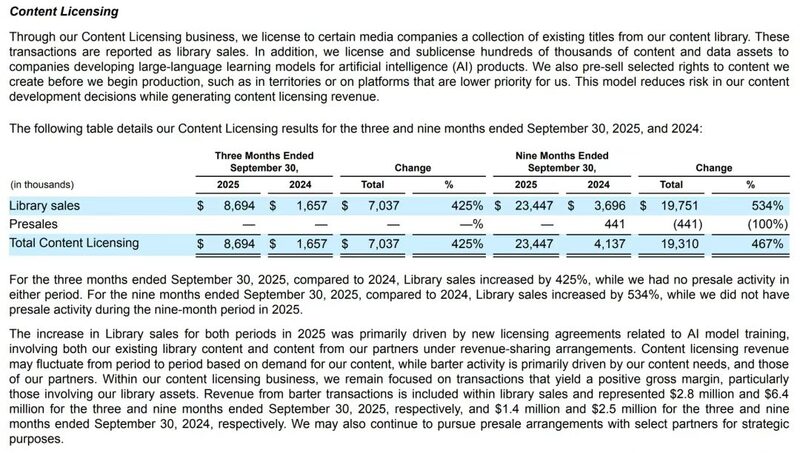
据透露,CURI 正在向 19 个 LLM(包括 Google Gemini)授权其 200 万小时的优质影视剧的内容。到 2026 年,CURI 认为其内容供给可翻倍、LLM 被许可方可增长约 50% 至约 30 个 LLM。在其已运行至少一年的 8 笔授权交易中,CuriosityStream 预计这些许可收入将在 2026 年实现翻倍。公司自有约 30 万小时内容,并对其平台上分发的其余 170 万小时内容采取与内容版权方五五分成的 LLM 费用分润模式。
因此,对那些多年思考“独特数据到底有没有商业化路径”的从业者而言,现在看起来确实“山里不只有矿,可能还有金”。
内容从卖给人到卖给机器的数据变现
如果您从事过广告行业,也许会觉得这并没有什么稀奇的:这不就是一种数据变现的一种新的方式嘛!
的确,数据变现并不是什么新鲜概念,尤其对于从事大屏广告行业的人而言。在这一行里,只要能捕捉到用户注意力的流向,就能把它转化成货币价值。在大屏广告行业,ACR(Automatic Content Recognition,自动内容识别)就是典型的商业化路径。它的基本逻辑是——当设备端通过指纹识别、音视频特征匹配等方式捕捉用户正在观看的内容数据(包括频道、节目、广告、使用时长、切换频次等),平台便可以将这些观看行为数据与广告曝光效果挂钩,卖给品牌主、媒体、代理公司,用于跨媒体归因、受众建模、内容运营与商业化优化。换句话说,ACR 把“注意力的客观流向”从原本离散的播出侧,转化为可量化的行为数据,再映射回商业价值。
发现没有,如果你理解了 ACR 的逻辑,再去看 CuriosityStream,反而更容易抓住它的独特性:两者都卖数据,但售卖对象与价值来源完全不同。
ACR 卖的是“观察到的用户行为”,因此它的价值链终点仍然是广告;而 CuriosityStream 卖给 LLMs 的,是“结构化的内容数据”,用途不是触达用户,而是训练模型,让机器具备更强的世界认知、概念联系与知识推断能力。一个提升广告效率,一个提升智能水平;一个依附于营销预算周期,另一个与算力和模型迭代周期绑定。从商业数学上看,前者赚取的是有限的注意力溢价,后者捕获的则是模型能力提升所带来的潜在复利空间。它们在形式上同为“数据变现”,但阶层差异犹如一次性资源与可积累资本的区别。
作为样本,CuriosityStream 至少证明了“内容即数据资产”这句话不再是一种空洞的口号,而是已经在真实的财务报表里显现。当数据供给不再依赖实时行为采集,而是依赖内容沉淀本身,媒体公司的收入结构出现了过去十年从未出现的新变量:内容的边际价值不止于消费,而延伸到了训练。
有人可能会问:视频不是给人看的么,为什么还能卖给模型公司,用来训练他们的大模型?
要回答这个问题,得先回到大模型的基本原理。所谓大语言模型,本质上仍是以海量文本为基础训练出来的“概率机器”,它擅长理解和生成语言,但文本并不能把世界讲清楚。模型如果只停留在“会说话”,它的能力边界就卡在语言本身;要进一步走向“会理解、会推理”,它必须接入更多维度的数据,其中最重要的来源之一就是视频。
原因不复杂。视频所承载的信息,恰好补上了文本的短板,并且主要体现在三个方面。
1、第一,纪录片、讲座、访谈等内容本身就是“压缩过的知识表达”。模型公司购买视频,并不是让模型直接去“看视频”,而是为了从中抽取结构、叙事与概念,把它重新“解压回”高质量的文本语料。换句话说,视频是文本的上游。
2、第二,视频是世界运转方式的可观测样本,包含时间、空间、因果与动作,这些规律若只依靠文字描述往往比较模糊,只有在影像里才会更加清晰。
3、第三,视频里天然存在语气、节奏、表达方式,这些细节决定了模型未来能否“像人一样解释与表达”,而光从纯文本里很难提取。这为多模态的训练提供了丰富的语料。
备注:最后拓展下,音视频数据其实还可以作为物理世界 AI 的训练,比如具身机器人,有兴趣的可以了解下如今机器人是如何训练的(因为机器人缺乏类似自动驾驶行业,拥有实际运行的丰富的车辆作为“影子模式”来训练,比如 Tesla)。

因此,视频的价值不在于“人喜欢看什么”,而在于“机器能从中学到什么”。这也是为什么,尽管流媒体平台众多,但并不是每一家都能得到模型公司的青睐。娱乐内容情绪丰富,但知识密度低、结构松散;而纪录片、科学与教育等内容则更具结构化潜力,能更有效转化为“高质量可训练数据”。
也正因为如此,像 CuriosityStream 这样专注于纪录片与知识内容的平台,天然处于这条赛道的优势位置。它的内容既足够密度,又足够结构化,是模型公司最缺的那类“有组织的数据”。
流媒体的内容价值重估体系
从这个意义上说,流媒体行业正在经历一次“机器视角的内容重估”——过去看内容,关注的是用户停留时长;未来看内容,关注的可能是模型能力能否因此变得更强。谁手里有“结构化的知识流量”,谁就更接近下一轮的智能红利。
一旦这条路径跑通,资本市场势必会重新评估媒体资产的估值方式:传统指标惯常衡量订阅续费与广告填充的可预测性,而在新的坐标系下,更重要的问题变成了两个——数据资产能否源源不断地产生?以及每单位数据在模型训练中的收益系数是多少?这不仅影响现金流结构,更会改变资产负债表中“内容库”的性质:在注意力经济里,它是一项折旧资产;在智能经济里,它可能演化为具有复利属性的长期资产。若这一判断成立,流媒体行业接下来真正的竞争力,不再是内容广度或用户增长速度,而是内容如何经由知识化、结构化与版权清晰化,最终成为能够被模型吸收的“训练燃料”。换句话说,谁能够持续提供可训练的数据,谁就掌握了下一轮资产重估的主动权。
因此,内容售卖给 LLMs 训练之所以能构成新型收入结构,原因不在于“数据又被卖了一次”,而在于它跨越了原有产业分工:内容不再只是面向用户的消费品,而成为模型能力的燃料。这意味着流媒体平台第一次能把沉淀内容转化为“智能红利”,而不是仅仅依赖订阅曲线或广告填充率。更直接地说,这条路径并非广告行业既有数据变现思路的延展,而是把内容从注意力经济带入智能经济的入口。
从这个角度回看过去十年,数据的价值主要体现在“告诉我们用户看了什么”,因为广告需要答案;但未来十年,数据的价值将更多体现在“让机器理解世界是什么”,因为模型需要知识。注意力会不断流动,算力会随时间贬值,内容会在语境演化中变旧,唯有能够沉降为模型能力的结构化知识,具备跨周期的长期效用。CuriosityStream 的案例不是巧合,它像是一次领先的证明:数据并非只有帮助卖广告这一条价值链,它还可以成为智能本身的原材料。这一转变的意义,也许会比人们现在意识到的更大。
风险与机遇并存
然而,每一种新的价值创造方式都会伴随风险。数据售卖给 LLMs 的争议并不小,尤其是版权与合理使用边界。在过去两年里,围绕模型训练产生的诉讼案例不断出现,举几个典型的例子:
1、Getty 指控 Stability AI 未经许可使用其大量版权图片训练生成模型,认为这不仅侵害版权,还直接影响其图库授权业务;
2、纽约时报称 OpenAI 在未获授权情况下抓取并使用其新闻内容训练模型,导致模型能生成与原文过于接近的内容,损害媒体原始报道价值;
3、多位作家联合起诉 Meta/OpenAI 等大模型公司,认为其作品被大量用于训练模型却未获得授权与补偿,模型输出内容还可能“模仿”其写作风格,构成版权与经济损害。

尽管最终判决尚未形成统一标准,但趋势已经清晰:未经授权使用内容进行训练具有显著法律风险,模型公司需要为训练的数据支付真实成本。这恰恰为拥有内容所有权的流媒体提供了“顺势而为”的机会——数据必须获取合法来源,而很多流媒体厂商正好拥有大量、持续、结构化且可确权的内容资产。版权争议的存在不是障碍,而是定价基础。
那么,接下来真正的问题不是“能不能卖”,而是“卖多少、卖多久、能持续吗”?
内容生产者不仅服务消费者,还服务模型
从产业视角来看,内容与数据的区别在于:内容消耗用户时间,数据提升机器能力。因此,数据资产的评估指标也不同:单位数据能给模型带来多大的误差下降?经过数次训练后,边际收益是否递减?内容是否具备持续更新能力以避免模型知识过时?在模型世界里,价值的计算接近数学——每单位数据的训练收益可以表示为模型能力提升的梯度贡献;而流媒体的商业生命力则取决于数据供应曲线是否具备长期产出能力。简单来说,数据不是一次卖完,而是能否成为“持续供能”。
我们可以做一个行业预测:如果模型公司的数据采购预算像算力一样成为固定支出,那么内容授权给模型训练可能成为第三条与“内容消费”“注意力变现”并列的主航道。在这个框架下,流媒体的竞争将从“谁拥有更多用户”转向“谁拥有更有价值的数据”,而后者与内容质量、结构化程度、版权清晰度、更新能力直接相关。产业分工极可能被重写:内容生产者不仅服务消费者,还服务模型。
若以时间为坐标,流媒体行业的收入模型可以这样概括:过去十年,我们靠内容与注意力赚钱;未来十年,我们可能靠智能增量赚钱。注意力的价值是线性的,智能的价值是指数型的;内容面向用户的生命周期有限,内容面向机器的生命周期可能更长。CuriosityStream 不是一次偶然的成功,而是率先证明“内容可以直接进入智能经济闭环”。当智能本身变成产品,训练数据将成为新的能源公司。
而掌握数据的,就是新的能源公司。因此,当我们讨论流媒体行业的未来时,或许比“谁的订阅用户更多”“谁的 ARPU 更高”更重要的问题是:谁能生产最有价值、最可训练、最具结构性的内容?谁能让内容从面向用户消费的产品,转化为面向机器学习的燃料?谁能把内容资产持续积累为数据资本?一旦行业在这三个问题上找到答案,收入结构的转折将水到渠成。与其说流媒体正在寻找新商业模式,不如说它正在进入另一条价值链——注意力经济是旧世界,智能经济是新世界,而内容卖给大模型训练,是跨过去的那座桥。

责任编辑:赵莹
24小时热文
流 • 视界










专栏文章更多
- [勾正科技] IPTV月报|2025年11月家庭智慧屏IPTV报告 2025-12-30
- [探显家] 当内容成为智能的燃料:流媒体的第二条价值曲线开始显现 2025-12-30
- [高书生] 高书生:“五点工作法”推动文化强国建设 2025-12-29
- [常话短说] 【重磅】专项资金支持,广电抓住! 2025-12-28
- [常话短说] 【解局】某省“广电+邮政”融合! 2025-12-26