




本文导读:本篇文章是“基于开源大模型库快速实现AI应用”的系列教程之一。在上一篇《大语言变换器模型的架构及其工作原理介绍》中,我们全面地探讨了Transformer大模型的起源、基本结构、工作原理以及其在自然语言处理等领域的应用。文章还深入分析了自注意力机制的核心原理、计算过程,以及多头自注意力的具体实现。通过详细的案例,我们解读了三种Transformer模型:纯编码器模型、纯解码器模型,以及编码器-解码器结合模型,并对它们之间的差异及应用场景进行了阐述。
在本文中,我们将从一个端到端的实例出发,展示如何直接利用模型和分词器类函数,复现文章《利用开源Transformer模型实现主要的NLP文本相关应用》中所介绍的管道(pipeline)功能。此外,你还将了解如何使用模型的各种API进行配置,这包括加载模型和处理数值输入,从而得到预测结果。我们还将深入探讨分词器的各个处理步骤和功能,并在文章末尾展示如何使用大模型进行多句子的批处理,以及相关的注意事项。
关键词:Transformer(变换器)、分词器、架构、检查点、模型。
1. Transformer 库的设计初衷
Transformer 模型往往规模巨大,参数从数百万到数十亿不等,因此训练和部署这些模型无疑是一项挑战。更为复杂的是,每天都有新的模型问世,而每种模型都有其独特的实现方式,这使得尝试各种模型变得困难。正是基于这些问题,Transformers 库应运而生。它旨在提供一个统一的 API,使得加载、训练和保存任何 Transformer 模型都变得轻而易举。
1.1. HuggingFace Transformer 库的亮点
该库主要具备以下特色:
• 用户友好:仅需简短的两行代码,你就可以下载、加载并利用业界领先的 NLP 模型进行推断。
• 高度灵活:库中的所有模型都基于 PyTorch 的 nn.Module 或 TensorFlow 的 tf.keras.Model 设计,因此你可以像处理其他机器学习框架中的模型那样,轻松地操作它们。
• 极致简洁:整个库的设计都力求简化,其中“一文件全包含”的理念尤为核心:模型的前向传播完全在单一文件中定义,这使得代码既容易理解又方便修改。
这最后一点使得 Transformers 库与其他机器学习库显著区别开来。模型不是基于多个文件中的共享模块来构建的,而是每个模型都拥有其独立的层次结构。这不仅使得模型更为直观和易于理解,还为用户提供了在特定模型上进行各种实验的便利,而无需担心会影响到其他模型。
1.2. 大模型相关的一些术语
在深入探讨Transformer模型时,我们经常会碰到“架构”、“检查点”和“模型”这几个词汇。为了帮助大家更清晰地理解这些概念,我们特地为大家详细解释一下它们的含义:
• 架构(Architecture):所谓的架构,其实就是模型的基本框架。它规定了模型中的各层结构以及这些层之间如何交互。简单来说,架构就像是模型的骨架,它决定了模型的基本构成和计算逻辑。
• 检查点(Checkpoint):检查点是模型在某个架构上经过训练后得到的权重。这些权重是模型在学习过程中获得的,用于实际的预测和分类。不同的检查点意味着模型在不同的数据上进行的训练,因此模型的效果也会有所区别。
• 模型(Model):这个词在不同的上下文中可能有不同的含义。它既可以指的是某个特定的架构,也可以是某个具体的检查点。为了避免混淆,我们在讨论时会根据上下文明确我们所说的是架构还是检查点。
以BERT为例,BERT其实是一个模型架构,描述了模型的基本结构和计算方法;而bert-base-cased是基于BERT架构训练出来的一个检查点,代表了一组特定的模型权重。在实际应用中,我们可能泛指基于BERT架构的模型为“BERT模型”,或者更具体地说“bert-base-cased模型”来表示加载了bert-base-cased检查点的模型。
2. Transformer管道的内部工作机制
在之前的文章中,我们介绍了如何利用HuggingFace Transformers库中的管道(pipeline)工具,仅凭几行代码便能轻松完成多种自然语言处理(NLP)任务。pipeline为我们提供了一站式的服务,从模型的加载、输入预处理、模型推断到输出后处理,都已经为我们妥善安排,使得即使对模型细节不甚了解的用户也能轻松上手。那么,当我们调用Transformers库中的pipeline函数时,它在背后是如何运作的呢?本文将深入探讨这一话题。我们将以情感分析为例,详细解读pipeline的工作流程,以及它是如何对以下两个句子进行分析,并判断其为“正面”、“中性”或“负面”情感,同时给出相应的置信度得分。
现在,我们先从一个熟悉的实例开始,这正是我们在前面的教程中为大家展示过的内容。
2.1. 变换器 pipeline 处理多个句子的情感分析示例
Pipeline还可以一次处理多个任务,即一次对多个句子进行情感判断。例如,给定两个句子:"我爱喝溧阳白茶" 和"夏天,我很讨厌蚊子咬我", 我们看一下如何通过 Pipeline 进行处理。

其输出结果为:

2.1.1. 代码解释
1. pipeline创建:我们使用pipeline函数创建了一个情感分析对象MyClassifier。这个对象被配置为使用lxyuan/distilbert-base-multilingual-cased-sentiments-student模型,这是一个多语言模型,专门用于情感分析。
2. 情感分析:我们传递了一个包含两个句子的列表给MyClassifier对象。这意味着我们一次性对两个句子进行情感分析。
2.1.2. 结果解读
输出结果是一个列表,其中每个元素对应于输入句子的情感分析结果。
对于句子"我爱喝溧阳白茶":
· 正面情感得分为83.96%
· 中性情感得分为11.74%
· 负面情感得分为4.30%
对于句子"夏天,我很讨厌蚊子咬我":
· 负面情感得分为77.64%
· 中性情感得分为13.76%
· 正面情感得分为8.60%
从结果中,我们可以看到第一个句子被判断为正面情感,而第二个句子被判断为负面情感。这与我们的直觉相符,因为第一个句子表达了对白茶的喜爱,而第二个句子表达了对蚊子的厌恶。
上面的管道整合了三个步骤:预处理、将输入传递给模型、以及后处理:

图 1 Transformer管道功能的三大步骤
下面让我们快速回顾一下这些步骤。
2.2. 管道处理步骤一-使用分词器进行预处理
与其他神经网络模型相同,Transformer模型不能直接处理纯文本。因此,管道处理的第一步是将文本转换为模型能够理解的数字形式。这一步骤需要使用分词器,其主要任务包括:
• 将输入文本分割成称为“令牌”的单词、子词或字符(例如标点符号)。
• 为每个令牌分配一个整数标识。
• 添加可能有助于模型理解的其他输入信息。
为了确保预处理与模型的预训练方式完全一致,我们需要首先获取与所使用模型相关的分词器信息。这些信息通常可以从开源模型库中找到。我们可以利用AutoTokenizer工具类及其from_pretrained()方法来实现这一目的。只需指定模型的检查点名称,它就会自动下载与该模型相关的分词器数据并进行缓存,从而避免重复下载。
由于sentiment-analysis管道默认使用的检查点是distilbert-base-uncased-finetuned-sst-2-english,我们需要选择一个支持中文分词的检查点。在本例中,我们选择了lxyuan/distilbert-base-multilingual-cased-sentiments-student。

获得分词器后,我们可以直接将句子传给它,得到的结果是一个Python字典,这个字典可以直接作为模型的输入。但在此之前,我们还需要将输入ID列表转换为张量格式。
使用HuggingFace的Transformers库的好处是,无论后端使用的是PyTorch、TensorFlow还是Flax,都可以轻松处理。但需要注意的是,Transformer模型只接受张量作为输入。如果你不熟悉张量,可以简单地把它看作是NumPy的数组,这些数组可以是标量、向量、矩阵或更高维的数据结构。

为了指定返回的张量类型,我们使用return_tensors参数。在本例中,我们希望返回PyTorch格式的张量,因此使用return_tensors="pt"。
我们先不用担心填充和截断参数,稍后会解释它们的作用。要记住的主要是,我们可以传递一个句子或一个句子列表给分词器,并可以指定您想要获取的张量类型(如果没有传递类型,您将得到一个列表的列表作为结果)。
上述代码的输出结果是一个PyTorch张量。

输出结果是一个包含input_ids和attention_mask两个键的字典。其中,input_ids包含了每个句子中令牌的整数标识符。我们稍后会详细解释attention_mask的含义。
2.3. 管道处理步骤二-模型内部处理流程
要下载我们需要的预训练模型,我们可以像获取分词器那样,使用AutoModel类的from_pretrained()方法:

在这段代码里,我们下载了之前在pipeline中用到的同一个检查点(实际上应该已经缓存了),并用它来创建了一个模型实例。
这个模型架构只包含了基础的Transformer模块:它接收一些输入,并输出我们称之为隐藏状态或特征的结果。对于模型的每一个输入,我们会得到一个高维向量,这个向量代表了Transformer模型对该输入的上下文理解。如果你现在还不太明白,没关系,后面我们会详细解释。
模型输出的这些隐藏状态既有其自身的价值,同时也是模型内部多头注意力机制的输入。需要注意的是,不同的任务可能会使用相同的模型架构,但每个任务都会有一个特定的head与之关联。
2.3.1. 高维向量解析
Transformer模块输出的向量维度通常很大,它通常包含三个维度:
· 批量大小:一次处理的序列数量(在我们的例子中是2)。
· 序列长度:序列的数值表示的长度(在我们的例子中是16)。
· 隐藏状态大小:每个输入的向量维度。
之所以称它为“高维”,是因为最后一个维度的值通常很大(例如,较小的模型可能为768,而较大的模型可能达到3072或更多)。
我们可以将预处理后的输入传递给模型,来查看这些向量:

输出结果为:

需要注意的是,Transformers模型的输出格式类似于namedtuple或字典。你可以通过查看返回结果的属性(如outputs.last_hidden_state.shape)或通过指定的键(如outputs["last_hidden_state"])来访问你想查看的部分。当然,如果你已经知道要查找的元素的位置,你也可以直接使用索引来访问(如outputs[0])。
2.3.2. 模型头机制:数字的解读
模型的头机制(模块)接收高维向量作为输入,并将它们转换为不同的维度。这些模块通常由一个或多个线性层组成。
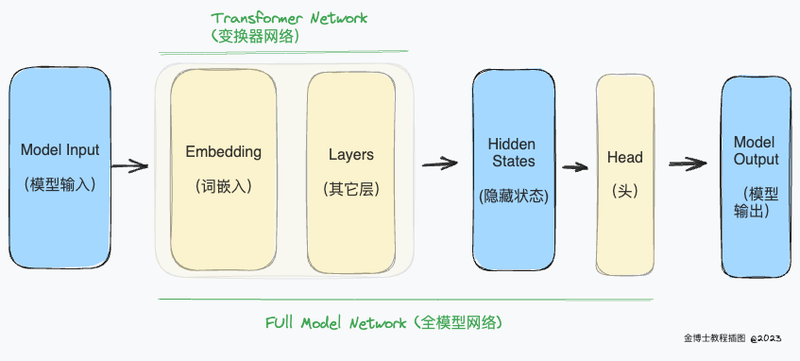
图 2 Transformer模型内部处理流程
Transformer模型的输出会直接传递给模型头模块进行处理。
在上图中,模型由其嵌入层和后续层表示。嵌入层将分词器输出中的每个输入ID转换为与对应token相关的向量。后续层使用注意力机制进一步处理这些向量,从而产生句子的最终表示。
Transformers库中有很多不同的模型架构,每种都是为了解决某个特定任务而设计的。例如:
· *Model(用于检索隐藏状态)
· *ForCausalLM
· *ForMaskedLM
· *ForMultipleChoice
· *ForQuestionAnswering
· *ForSequenceClassification
· *ForTokenClassification
· ...
回到我们的例子,我们需要一个具有序列分类功能的模型头(以便将句子分类为正面、中性或负面)。因此,我们不再使用AutoModel类,而是选择AutoModelForSequenceClassification类:

现在,查看输出的形状,你会发现维度变小了:模型的头机制接收了我们之前看到的高维向量作为输入,并输出了包含三个值的向量(每个标签一个):

因为我们只有两个句子和三个标签,所以模型返回的结果的形状是2 x 3。
如果我们将logits打印出来,print(outputs.logits),输出如下:

在接下来的章节中,我们会对这些值进行进一步的处理,使得普通用户可以更直观地理解它们的含义。
2.4. 管道处理步骤三-模型输出的后处理
我们从模型中得到的输出值本身可能不直观,需要进一步处理以获得实际的预测结果。以两个中文句子为例:"我爱喝溧阳白茶" 和 "夏天,我很讨厌蚊子咬我",我们可以观察模型对这两句话的处理结果:

模型为"我爱喝溧阳白茶"预测了[ 1.6023, -0.3653, -1.3690],为"夏天,我很讨厌蚊子咬我"预测了[-0.7965, -0.3268, 1.4034]。这些数值不是我们通常理解的概率,而是所谓的对数几率(logits),即模型最后一层输出的原始、未经归一化的分数。要将这些对数几率转换为概率,需要经过一个SoftMax层。

经过SoftMax层处理后,模型对"我爱喝溧阳白茶"的预测变为[0.8396, 0.1174, 0.0430],对"夏天,我很讨厌蚊子咬我"的预测变为[0.0860, 0.1376, 0.7764]。这些数值已经转换为了我们熟悉的概率分数。
为了获取与每个位置相对应的标签,我们可以查看模型配置中的id2label属性:

综合以上信息,我们可以得出模型的最终预测:
· 对于"我爱喝溧阳白茶":NEGATIVE: 0.0430, POSITIVE: 0.8396,模型以较高的概率预测该句子为正面情感。
· 对于"夏天,我很讨厌蚊子咬我":NEGATIVE: 0.7764, POSITIVE: 0.0860,模型以较高的概率预测该句子为负面情感。
2.5. 管道内部工作流程小结
至此,我们已经成功地复现了管道(pipeline)的三个步骤:使用分词器进行预处理,将输入传递给模型,以及后处理。
在`pipeline`中,我们首先遇到的是分词阶段,其中文本被转换为模型可以理解的数字形式。这个过程不仅仅是简单地将文本分解为tokens(如单词或标点符号),分词器还会为模型添加特定的tokens,例如CLS和SEP。每个token都与一个唯一ID相匹配,而这些ID是通过Transformers库中的`AutoTokenizer` API加载的。
接下来,数字化的文本数据被送入模型进行处理。虽然我们可以使用`AutoModel` API来下载模型的配置和预训练权重,但这只会给我们模型的主体部分。为了得到与我们的分类任务相关的输出,我们实际上需要使用`AutoModelForSequenceClassification`类,这个类会为我们构建一个带有分类头的模型。
最后一个阶段是后处理,这是将模型的输出转换为实际分类结果的地方。模型输出的`logits`首先通过SoftMax层被转换为概率。然后,我们使用模型配置中的`id2label`字段来确定哪些概率对应于哪些标签。
这三个阶段虽然各自独立,但都是为了最终的目标服务的:将原始文本转换为有意义的分类结果。现在,了解了这些步骤的工作原理后,用户可以更加灵活地根据自己的需求调整它们。
责任编辑:房家辉
24小时热文
流 • 视界










专栏文章更多
- [探显家] 好莱坞的“浮士德交易”:Paramount 和 Netflix 的竞购之战 2025-12-16
- [常话短说] 【解局】某广电向不良资产动刀 2025-12-16
- [常话短说] 【热评】广电做“错”了什么?! 2025-12-15
- [常话短说] 【重要】广电“壮士断腕”! 2025-12-11
- [常话短说] 【解局】广电降本增效“大有空间”?! 2025-12-10