




我关注 Doug Shapiro 有很长段时间了。他出身华尔街分析师,做过 Turner Broadcasting 的 CSO,现在是 BCG 的高级顾问,行文一贯冷静,少见激动的修辞。

此前我曾编译过他的一篇关于 GenAI 的长篇演讲,信息量极大、非常精彩,有兴趣的可以回顾。
最近,他发表了一篇新文章《Computable Meaning and Computable Information》,这次则给了我一个不小的惊喜。文章开头,他坦率地承认:过去三年自己一直在写、在讲 GenAI 对媒体行业的影响,但越写越觉得,之前把问题看得“太窄了,把它说小了”。

对于一向冷静的 Shapiro 来说,这是他少有的、带点自我修正意味的表述。
他现在的判断是:GenAI 远远不止"内容创作又一次被颠覆"这么简单,它更像是一场“信息时代的范式切换”。为了支撑这个结论,他没有走那种“AI 会改变一切”的大口号路线,而是从第一性原理重新把整套逻辑推演了一遍。我读完之后,把他的推演在脑子里又过了一遍,再对照自己这几年在媒体、娱乐和科技这条线上的一线观察,越想越觉得这个框架值得认真展开。于是,就有了这篇文章,算是结合 Shapiro 的原始视角和我自己的思考,做一次系统性的拆解和延展。
三个信息时代:一个被压扁的视角
Shapiro 在文章开头就摆出了他的整体框架。三层结构,时间线长达近一个世纪。
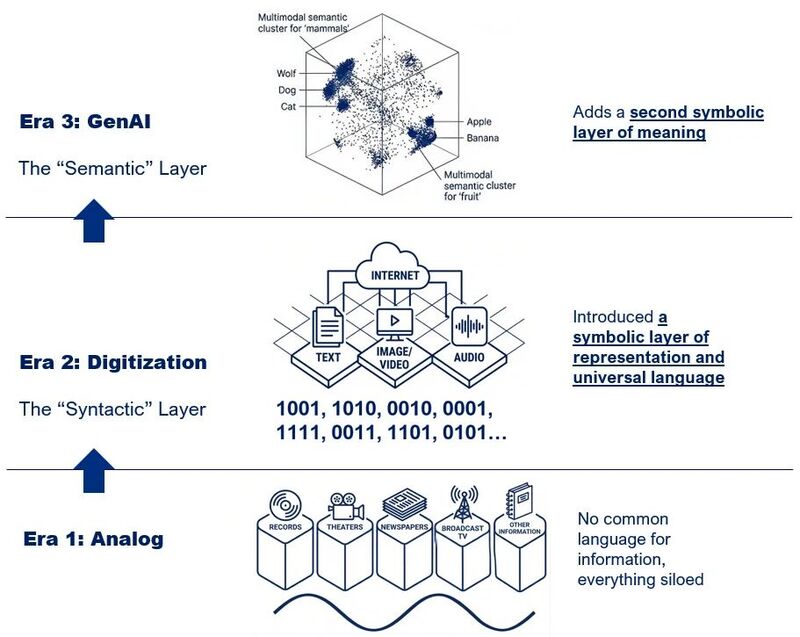
这张图所呈现的信息密度比看上去要大,从最早的 Era 1 到最新的 Era 3,都被压缩在这一张里。我就顺着这三层,从下往上给你拆开讲讲。
最底层是模拟时代。唱片、电影、报纸、广播电视和其他内容形态,就像五个彼此隔绝的“盒子”,盒子和盒子之间几乎没有通路。图里底部那条波浪线,代表的就是这些媒介共同依赖的模拟信号本身。这五个行业各自在自己的轨道上演化了几十年,谁也不依赖谁。
中间这一层是数字化。文字、图像/视频、音频被一朵名为“互联网”的云连接起来,下面是一串 0 和 1。Shapiro 把这一层命名为“语法层”:在这里,一切内容都被压扁成统一的比特流,机器只关心如何准确传输符号,不关心这些符号到底“表达了什么”。
最上面这一层是 GenAI。图里画的是一个三维语义空间,“狼、狗、猫”在一侧扎堆(哺乳动物),“苹果、香蕉”在另一侧成团(水果),多模态的语义簇围绕着这些概念分布。这一层被称为“语义层”:系统不再只是搬运比特,而是可以直接在“意义空间”里做运算。
关键在于,这三层不是彼此替换,而是层层叠加。语义层不会抹掉语法层,而是运行在语法层之上;语法层也不会抹掉模拟世界,而是建在模拟世界之上。每一层都把下一层当成自己的地基。这也是这个框架最有意思的地方:它讲的是一个“新东西在旧东西之上长出来”的故事。每抬升一层,可能性空间就被整体放大一个量级。接下来,我会按这三层的顺序,逐层拆开它们各自意味着什么。
第一层:模拟时代
Shapiro 引用了自己的旧作《Infinite Content》里的一段论述。大意是:自然界本身是连续的、模拟的。声音是空气压力在时间上的连续起伏,光是在频率上连续分布的电磁波。在数字技术商用之前,所有媒介要还原这些声音和图像,都必须复刻这种"连续性"本身。
声音被刻在黑胶上,是一段被物理放大、再用唱针刻进沟槽的波形。声音被录在磁带上,是一段被磁化的氧化铁颗粒。图像被印在感光纸上,是经过化学反应的银盐颗粒,颗粒越细,分辨率越高。文字稍微特殊,它本身就是一种对语言的抽象,而语言又是对人类思维的抽象,但在模拟时代,文字最终也要落在纸张上,作为一个个铅字被印出来。
也就是说,每一种媒介都有自己完全不同的“原子单位”。
这件事带来的后果,不只是技术层面的,而是直接塑造了产业结构。一首歌的最小单位是一个音符或一段波形,一部电影的最小单位是一帧画面或胶片上的颗粒,一段文字的最小单位是一个字母。它们之间没有共同语言。没有共同语言意味着没有统一的处理方式:唱片机播不了电影,广播塔传不了报纸,电视机里看不到书。
更深一层,商业组织也被迫沿着这条物理边界生长。每一种模拟媒介都演化出了自己独立的产业链:自己的供应链、终端形态、发行渠道、版权制度、工会和监管体系。好莱坞的电影业和纳什维尔的唱片业、纽约的出版业、洛杉矶的广播业,看上去都属于"娱乐业",但它们的内部结构完全不同,互相之间几乎没有人才流动。
公司档案的世界更是如此。在数字化之前,企业的资料被困在文件夹、清单、缩微胶片里。一份 1970 年代的公司合同,理论上“存在”,但要真正用起来,得有人去库房,一箱箱翻档案盒。它在那里,却几乎不可被计算、不可被搜索、不可被编排。
这种碎片化,并非各行各业不愿打通,而是底层介质从一开始就划出了边界。介质本身,构成了一种看不见但非常刚性的结构约束。
第二层:数字化与语法层
1948 年,Claude Shannon 在贝尔实验室(当时在纽约西村)发表了那篇奠基之作《A Mathematical Theory of Communications》,刊登在了《Bell System Technical Journal》上。这篇论文开创了信息论这个学科,也引入了"比特(bit,binary digit)"这个概念,也就是构成所有现代通信最底层的、无处不在的 0 和 1。
Shannon 把一件直觉上模糊的事情,形式化成了严谨的数学结论:任何一个模拟信号,都可以被二进制代码在原则上“完整”地复现出来。我们今天所说的“数字化”,本质就是沿着这条路径,把连续的物理世界压缩成可计算的比特流。
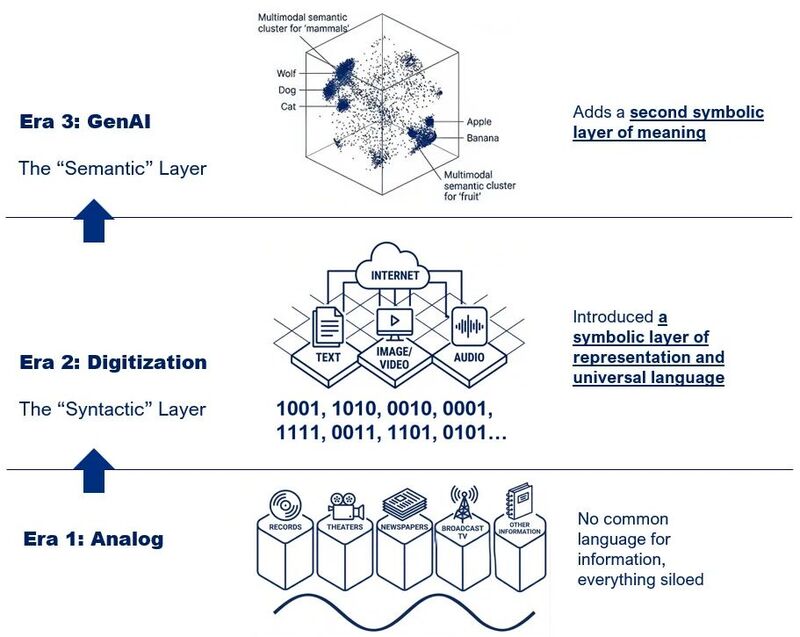
Shapiro 在文中画了一张四步图。
第一步,是原始的模拟信号(Analog Signal)。一段连续起伏的波形,可能是一段声音、一段视频画面的亮度变化,或者任何模拟信号。
第二步,是采样(Sampling)。在时间轴上以固定的间隔切片,把连续的波形变成一组离散的点。采样频率越高,对原始波形的还原越精细。CD 的 44.1 kHz、电话的 8 kHz,都是不同精度的采样选择。
第三步,是量化(Quantization)。每一个采样点的高度,被映射成一个具体的数字。原本无限精细的振幅,被映射到一组有限的整数刻度上。这一步必然会损失一部分信息,但也是数字化能进行下去的前提。Shapiro 在文章里把这一步等价地叫作"数学化(mathematizing)":把现实世界的物理量,硬生生转成一个可以被数学运算的对象。
第四步,是编码(Encoding)。每一个量化后的数字,都被转换成二进制代码。9 对应 1001,8 对应 1000,依此类推。
经过这四步,一段原本只能用某种特定物理介质承载的模拟信号,被转化成了一串纯粹的数字。这串数字脱离了物理介质:它可以被复制、被传输、被存储在任何能够读写 0 和 1 的设备上,且理论上不损失任何信息。
这就是数字化为什么是革命。它给所有信息形态(文字、数字、图像、音频、视频)提供了一种统一的编码方式。同一台机器,同一套基础设施,同一个网络,可以处理所有这些原本彼此孤立的媒介。
这个命名是有意为之的。它来自语言学:语法关心的是符号的结构、规则、组合方式,但语法本身不负责"意义"。一个句子可以语法正确但毫无意义("无色的绿色想法愤怒地睡觉"),也可以语法不规范但意义明确("他这个人,是挺聪明,但是就是不太靠谱")。
数字化建立的就是这样一种"与意义无关"的通用语言。它只在乎比特是否按规则排列,对这些比特所承载的内容是无感的,对内容是不是有意义、意味着什么,统统不关心。
Warren Weaver 专门给 Shannon 那本书写过前言,他把通信问题分成两层:一层是"技术问题",问的是"符号能多准确地被传输出去";另一层叫"语义问题",问的是"传过去的符号能多精确地传达意义"。Shannon 自己在论文里也说得很直白:通信的语义层面,与工程问题无关。
换句话说,数字化解决的,从一开始就是技术问题,不是语义问题。
但正是这种"对意义的无视",让数字化变得极度普适。一个图书馆员、一家银行、一座广播电台,内容形态完全不同,却都可以用同一套硬盘、同一套网络协议、同一套机房基础设施。语法层不关心内容是什么,所以语法层能承载一切内容。
过去三十年,我们看到的那些所谓"被数字化颠覆的行业",比如零售业被电商颠覆,出版业被互联网颠覆,唱片业被流媒体颠覆,传统电视业被 OTT 颠覆,这些本质上都是这一层红利的延后兑现。每一次颠覆的内在逻辑都很相似:把原本绑在物理介质上的内容解放出来,让它们以接近零的边际成本被复制和分发。
第三层:GenAI 与语义层
在第三层,Shapiro 画了一张关于 GenAI 的示意图,试图回答一个问题:模型到底在“意义”这个层面上做了什么。
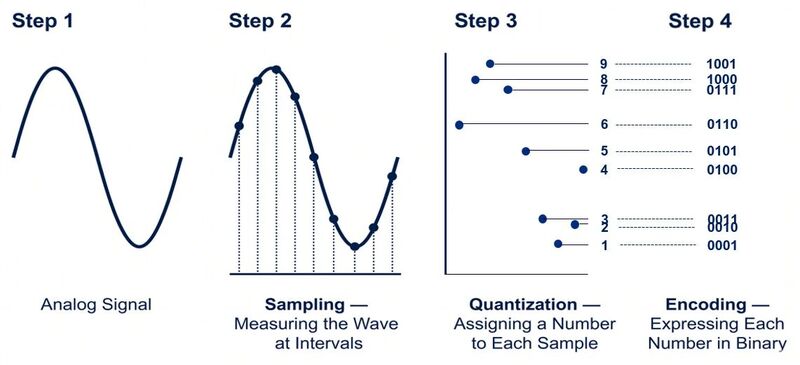
第一步,是输入。文档、词语、概念被统统喂进一个机器。
第二步,是向量化。每一个词、每一段文本被映射成一组数字。在真实的大模型里,这组数字有几千上万个维度。"猫"可能是 [0.91, 0.45, 0.12, ...],"狗"是 [0.88, 0.49, 0.15, ...],"狼"是 [0.85, 0.52, 0.18, ...],"苹果"是 [0.08, 0.82, 0.91, ...],"香蕉"是 [0.05, 0.79, 0.88, ...]。这些数字对人而言几乎不可读,但它们之间的"距离"是有意义的:值越接近,表示语义上越接近。
第三步,是形成"语义空间"。当所有这些向量被放进同一个高维空间里,它们会自动聚集。猫、狗、狼挤在一起,因为它们都是哺乳动物。苹果、香蕉挤在另一边,因为它们都是水果。这种聚集不是有人手工标注的结果,而是模型在海量文本上做统计学习时自然涌现的副产品。
也就是说,GenAI 在做的,是先把语言压成一团高维数字,再在这个数字空间里,让“意义之间的关系”变成可以被直接计算、比较和重组的对象。
为什么"意义可计算"才是真正的范式跃迁?
在数字化时代,"猫"这个词的二进制表示,和"狗""鱼""桌子""彩虹"的二进制表示之间,没有任何"距离上的可比性"。它们只是一串字符编码,完全按 ASCII 或 UTF-8 排列,相邻不代表相似。
在 GenAI 时代,"猫"和"狗"的向量距离,比"猫"和"桌子"的距离小,比"猫"和"彩虹"的距离更小。这种距离是机器可以直接计算的。
也就是说,"语义"(意义之间的关系)第一次成了一种可以被数学操作的对象。
Shapiro 把这一层叫作"语义层(semantic layer)",把这种能力概括为一句话:数字化让"信息"变得可计算。GenAI 让"意义"本身变得可计算。
这是整篇文章的核心。后面所有的推演,都从这一句出发。为什么"意义可计算"是一件更大的事?
Shapiro 在这里给出了几个理由。我把它们逐条展开。
第一,价值的位置变了
信息的终极价值,从来不在“路”上,而在“货”上——不在于它是怎么被运来的,而在于它到底承载了什么意义。数字化解决的是前者,是一个典型的“运输问题”;GenAI 则开始正面撕开后者,直接进入“内容物”的内部。
打一个比方。过去几十年,我们一直在修更宽、更直的公路:车速更快、通行能力更强、运输成本越来越低,几乎任何东西都能从 A 点高效送到 B 点。互联网就是这条超级高速路。它不关心车里装着什么,只负责把车按时送达。
而现在,GenAI 带来的是另一种能力:我们可以打开每一辆车的后备箱,读懂里面装的是什么,还能重新整理、改写、重新打包这些“货物”,甚至组合出全新的货物形态。这两件事的尺度完全不在一个量级上。运输优化有一个自然极限,你再怎么卷,也不可能比“免费 + 即时”更快更便宜了;但“内容物”的优化几乎没有天花板,你永远可以讲一个更好的故事、给出一个更精确的解释、做出一个更聪明的决策。对所有信息密集型行业,这个逻辑都成立;但在媒体娱乐行业里尤其直观,因为这个行业卖的本身就是“信息”。一部电影真正的价值,不在于它是院线首映、电视播出,还是流媒体点播,而在于它讲了一个什么故事、给观众带来什么情绪和认知;一首歌的价值,也不在于它用哪家播放器播放,而在于听众被哪一句歌词、哪一段旋律击中了。当“意义”本身可以被计算、被评估、被改写、被重组时,价值不再停留在“谁掌握了通路”的层面,而是开始向“谁掌握了对意义的处理能力”迁移。对任何靠信息吃饭的行业来说,这意味着一件事:原本围绕分发端搭建起来的那条价值链,迟早要在“语义层”上被重新画一遍。
第二,原语的数量级不一样
这一点我觉得是 Shapiro 整篇文章里最被低估的洞察。
在编程里,"原语(primitives)"指的是一个系统最基本的、不可再分的操作。你可以用原语组合出复杂的程序,但原语本身是给定的。
打个比方,乐高的原语就是那几种基本积木。再宏伟的城堡、飞船,最终也是这些积木拼出来的;英语的原语是 26 个字母,再厚的小说也是这 26 个字母的组合。数字化时代的计算机,原语非常少。基本上就是 read(读)、write(写)、copy(复制)、move(移动)、delete(删除),加上 concat、split、compare 这些比较类的。一台计算机能做的事,无论多复杂,最终都可以分解成这几个动作的组合。这套动作几十年没变过,而且也不会再变了。语义计算的原语集合是开放的。Shapiro 在文章里列了一组:create(创造)、coordinate(协调)、translate(翻译)、convert(转换)、transform(变换)、evaluate(评估)、verify(验证)。还可以继续往下列:summarize(总结)、explain(解释)、negotiate(协商)、persuade(说服)、critique(批评)、teach(教导)、moderate(调解)、imagine(想象)……关键的差别就在这里:传统计算机的工具箱里只有几把工具。GenAI 的工具箱里有几十把工具,而且还在不断有新的工具被加进来。工具数量的差别会被组合空间放大。3 把工具能组合出的工作流,和 30 把工具能组合出的工作流,可不是简单得 10 倍的差距,而是阶乘式的差距。"翻译 + 总结 + 评估"和"评估 + 翻译 + 总结"是两条不同的链路;"对一段视频做转录、再翻译、再风格改写、再事实核验"是一条;"对一份合同先做摘要、再做风险评估、再生成谈判建议、再起草反提议"是另一条。每多一把工具,可能的组合数都在指数级增长。
每一个原语都对应一种"对意义做某种处理"的能力。它们不是固定的指令集,而是可以根据任务被定义出来的能力。
第三,agent 让链式编排变成复利
如果说语义原语的组合空间是庞大的,那么 agent 是把这个空间真正可用化的工具。
一个孤立的语义原语调用,能做的事是有限的。但当一个 agent 可以记忆、可以规划、可以调用其他 agent、可以使用工具(搜索、代码、数据库、API)、可以自己判断什么时候该调用哪一步的时候,它的整体能力就不再是单个原语的简单相加,而是乘法关系。
这一点对应着一个被反复观察到的现象:模型本身的能力提升是渐进的,但「模型 + 工具 + 编排」的整体系统的能力提升是非线性的。同样一个模型,单独使用 vs 放进一个有规划能力的 agent 框架里,能完成的任务复杂度可能差几个量级。
而 agent 框架本身也在快速迭代。我们正处在一个复利结构的早期:模型变好 → agent 框架变好 → 整体系统变好 → 反过来又拉动模型和框架进一步迭代。
数字化时代有过类似的复利结构吗?有过一次,那就是「摩尔定律 + 互联网带宽增长 + 软件生态扩张」这三条曲线的叠加。它们花了三十多年时间,重塑了几乎所有行业。GenAI 的复利结构刚刚启动,但它的输入侧(意义)比"信息"更接近行业价值的核心。
第四,语义层不是中立的
这一点 Shapiro 没有直接展开,但我觉得对所有内容产业都是关键的。
语法层是中立的。0 和 1 不偏爱任何内容形态。同一段比特,是一首歌还是一份合同,对底层网络协议来说没有差别。
然而,语义层不是中立的。
它会主动地理解内容、对齐用户上下文、生成新的关联。它会判断什么是相关的、什么是无关的,什么是好的、什么是差的,什么应该被推送、什么应该被过滤。
这意味着任何"内容遇到用户"的中间环节(推荐、检索、广告、客服、个性化、版权识别、内容审核)都会被重新洗一遍。在数字化时代,这些环节是以规则、关键词、协同过滤、统计模型的方式工作的,每一个环节都有它的局限。在语义层时代,这些环节会被重写为对"意义"的直接处理。
这件事的影响范围比内容创作要大得多。因为在媒体娱乐行业里,"创作"只是价值链上的一段,而"内容遇到用户"是贯穿整条链路的。
一个必须诚实面对的差异
Shapiro 在这里点破了一个很多人刻意忽略的问题。
语法层的计算,是客观、确定的。1001 这一串比特,发出去还是 1001,不会因为对端是谁、在什么语境里,就“自发”变成 1010。同样的输入,喂进去一千次,理论上一千次都该得到完全一致的输出。
语义层完全不是这样。它是上下文相关的,是概率分布,而不是固定答案。
同一段输入,喂给不同的模型、配上不同的 system prompt、放在不同的对话历史里,输出可能完全不同。即使是同一个模型、同一个 prompt,两次调用之间也可能产生不同的结果。
这件事直接决定了 GenAI 在知识工作上的自动化路径不会是均匀的。Shapiro 给出了两个坐标轴:一是任务的利害程度(stakes)有多高,二是结果是否可以被客观、可重复地验证。
这两个变量交叉之后,世界就被切成了四大版图。
版图一:stakes 低、可验证性高的任务
比如把一篇英文文档翻译成西班牙文、给一段代码生成 unit test、根据结构化数据画一张图。这类任务的特点是:出错成本很低,而且对错很容易被机器或人立刻检出。它们会以极快的速度、在极高比例上被自动化掉。先是“AI 主做,人类抽检”,很快发展成“AI 全包,人类只在出问题时介入”。
版图二:stakes 高、可验证性也高的任务。
比如医疗影像的初筛、复杂合规文本的检查、财报数据的提取和核对。这些任务一旦出错,代价很大,但结果又相对容易用第二套系统来验真。这里更可能形成的是“AI 先做,人类复核”的工作流:AI 做大规模预筛、预判,人类负责最后一层把关。自动化比例依然会很高,但人类必须牢牢待在环路里。
版图三:stakes 高、可验证性低的任务。
比如企业战略决策、并购判断、复杂的人际谈判、内容 IP 的中长期布局、创意方向的选择。这类任务出错代价巨大,却往往缺乏一个“事后能算出标准答案”的评估机制。今天做的决策,是不是五年后才知道对错?在这种区域,AI 更像一个智囊团和模拟器:负责帮你生成备选方案、建模不同情景、暴露盲点和假设,甚至扮演对手方、董事会、监管者来反向拷问你。但谁来拍板,还是人类。
版图四:stakes 低、可验证性也低的任务。
比如写一篇博客、起一个营销 slogan、构思几版广告创意、帮你想一些 campaign 主题。这里出错也没什么大事,成败标准又高度主观,往往是“好不好看”“像不像这个品牌”“观众买不买账”。这种区域会被大面积外包给 AI,人的角色从“亲手写”变成了“挑选 + 调教风格”:你不再一字一句从零写起,而是在 AI 提供的候选里挑、改、融合、定调。
Shapiro 想说的是:在人类知识工作这条长链条上,AI 的渗透不会是一条平滑的“平均曲线”,而是一个高度分区、节奏完全不同的版图。从这个角度看,“AI 会不会取代多少岗位”这个问题本身就有点模糊。更精确的问法应该是:在每一条业务链条上,人类会从哪一段环节开始后撤,AI 会往哪一段环节挺进,各自的边界线会怎么移动。
而这篇文章还有一段争论,我觉得特别值得单独拎出来讲一讲。
A&O Shearman 的 Tim Carter 直接质疑了 Shapiro 的“语义可计算”这个说法。他的核心观点是:意义从来不是被"装"进信息里再被对方"拆"出来的,意义是接收者在自己的心智和语境里现场构造出来的。
换句话说,在他看来:所谓“语义计算”这个词,本身有误导性。GenAI 处理的不是一个个装着固定意义的小包裹,而是在不断打散、重组上下文,重新构造解释关系;在这个过程中,它既可能帮你澄清意义,也可能扭曲、甚至摧毁原有的解释链。从这个视角出发,他认为:GenAI 与其说是"数字化的下一层飞跃",不如说是数字化体系里开出来的一个巨大、危险、但极具潜力的子目录。Shapiro 的回应并没有“硬刚回去”,而是部分接纳、部分坚持:他认同一点:用户感知到的意义,确实是「模型 + 上下文 + 用户」三方共同构造出来的,而不是一个客观的“语义粒子”被原封不动地搬来搬去。但他坚持认为,正是因为这一层"对用户意义的主动加工"真实存在,我们反而更有理由把它抽象成一个"语义层"来讨论:它不是客观实体,却是一个足够稳定、足够强的结构性力量。有趣的是,这场小小的交锋,帮我们把"意义可计算"这个说法的边界倒是画清楚了:1、语义层并不是一个客观、单一的"意义仓库";2、它更像是一套在不同上下文中、反复重构意义的机制;3、这一层能被计算的,是"在给定上下文下,某种解释的相对合理性和关联度",而不是"永恒正确的含义"。承认这一点,反而让 Shapiro 的三层框架更扎实:我们不再把“语义层”神化成一个绝对真理机器,而是把它视作一个强大的、但永远带着偏见和噪音的"意义加工层"。从工程视角看,这依然足够革命;从社会视角看,它也解释了为什么 GenAI 既能放大洞见,也能放大误解。
对媒体娱乐行业的启发
Shapiro 在文章末尾给出了一句对媒体行业的提醒:GenAI 对媒体的冲击不只是"内容创作变得便宜了"。Create 只是语义原语中的一个。Coordinate(协调)、translate(翻译)、convert(转换)、transform(变换)、evaluate(评估)、verify(验证)每一个都有可能改写一段价值链。
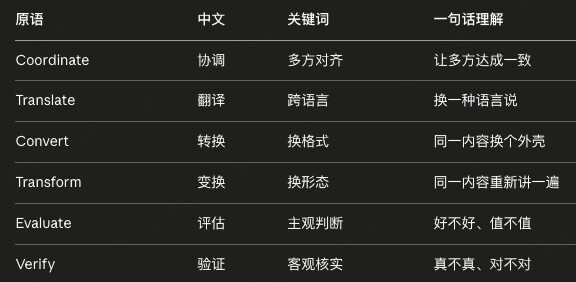
我顺着他的思路,把这些原语放在媒体娱乐行业的语境里走一遍。这一节我刻意不聚焦在某一个细分赛道,因为这个框架的适用范围远比一个赛道要大得多。
Translate 正在重塑全球分发的经济学
多语言字幕、配音、本地化营销文案的成本曲线在过去几年里被不断压低。
这件事的影响是全球性的。Netflix、Disney+、Spotify、YouTube 这些全球性的流媒体平台过去都面临一个根本性的取舍:一部内容值不值得做本地化,要算一笔账,本地化成本能不能被本地市场的收益摊薄。这条曲线决定了哪些内容能进入哪些市场,进而决定了哪些市场的用户能看到哪些内容。
当本地化成本接近于零,这条曲线就会整体下移。长尾内容的国际分发被打开了。一部小众的法语剧集,过去不值得为它做西班牙语字幕,因为西班牙的潜在订阅增长支撑不住成本;现在值得了。
这件事对碎片化语言市场的影响最大。东南亚、拉美等这些区域的语言碎片化程度高,市场单体规模小,过去一直是国际内容分发的"次优先级"。语义层的成本下降,会让这些市场第一次有可能被认真对待。
Coordinate 是被低估的原语
媒体娱乐行业本质上是一个高度协调密集型的行业。
一部好莱坞电影,从开发到上映,要协调编剧、导演、演员、制片、特效、发行、院线、营销、衍生品、流媒体窗口几十个角色。一档综艺节目,要协调嘉宾、场地、赞助、版权、平台、剪辑、推广。一次广告投放,要协调品牌方、代理商、媒体方、创意、监测、合规几方。
每一次协调的本质,都是"在多方上下文里达成一致的语义"。
这件事是 GenAI 最擅长的事之一,但也是过去最难自动化的。因为它没有清晰的输入输出,没有客观的对错标准,依赖大量的隐性知识和心照不宣的沟通默契。
语义层让这种协调第一次有了规模化的可能。AI 可以读所有相关方的邮件、合同、会议记录,可以理解每一方的诉求和约束,可以生成对所有人都自洽的方案,可以在多方之间做即时的翻译和调解。这件事的影响范围远比"AI 写剧本"要大得多,因为它触及的是这个行业的中间层,是所有那些"让事情真正发生"的环节。
Evaluate 和 verify 会改写整个广告和品牌生态
广告/内容品牌安全、内容适配性、创意质量审核、版权识别、虚假信息识别、归因分析......这些工作过去都依赖采样和规则。
采样的局限是显而易见的:你看不到全貌。规则的局限同样明显:现实世界的语义复杂度,永远超过任何规则集能覆盖的范围。
语义层让"逐条理解每一支广告每一帧画面"成为可能。这是一个质的变化。过去广告主问"我的广告投放在哪些环境里",得到的是统计学意义上的回答;现在可以得到逐条精确的回答。过去版权方问"哪些内容侵权了我",得到的是基于指纹匹配的回答;现在可以得到基于语义相似度的回答,连改头换面的衍生作品都能识别。
这件事会重新分配产业链上的话语权。能掌握"语义级理解"的环节,会获得更多议价能力。
Transform 改写的是内容形态本身
一部长视频可以被自动拆成短视频,可以被压缩成图文摘要,可以被改写成多语种的播客,可以被生成为社交媒体的预告片,可以被改编成互动游戏的脚本。一档综艺可以被自动剪辑成几十个独立的片段,每一个片段都对应一个不同的传播场景。
因为从事行业的关系,我对"多屏幕"这件事有着特殊的认知。多屏幕背后都有一套独立的观看逻辑:客厅大屏是共享的、长时段的、被动消费的;手机是 lean-forward 的、私人的、碎片化的、主动消费的;车载屏是分心场景下的辅助消费,注意力随时被路况打断;户外屏是无声的、单向的、几秒之内必须传递完信息的。同一份内容要在这些屏幕上都成立,过去几乎不可能。一部电影,影院版本是 120 分钟、为黑暗环境和巨幕音响设计、依赖长镜头积累的情绪张力;它的短视频版本必须在前 3 秒抓住人,在 30 秒之内完成一个独立的情绪曲线;它的车载音频版本要能在没有画面支撑的情况下自洽,台词和音效要承担起原本由画面承担的叙事任务;它的户外屏版本可能只能保留一个标志性画面加一行字,要在 3 秒之内让一个完全没看过这部电影的人产生兴趣。需要的是同一份内容的重新创作,只不过是带着原始素材的重新创作。这件事过去要靠大量人力。一家电视台或流媒体平台做"全平台分发",是一项昂贵又繁琐的工程,需要后期、剪辑、运营、社媒、本地化几个团队配合。每一块屏幕都有自己的内容团队,每一支团队都在做"把同一个故事用这块屏幕的语言重新讲一遍"的工作。语义层让这件事第一次具备规模化的可能。AI 不只是会"剪短",它开始理解每一块屏幕背后的观看语法,然后按那块屏幕的语法重新生成内容。它知道客厅大屏的开场可以慢,因为观众坐下来了;它知道手机短视频的开场必须快,因为刷一下就划走了;它知道车载场景下信息要冗余一点,因为驾驶者的注意力随时会被路况打断。
不只是在头部平台,在中小媒体、个人创作者、品牌自媒体的层面,这种能力都在被逐步释放。
这件事的影响是结构性的。当"内容生产 → 多形态分发"的成本接近于零,"形态优势"就消失了。过去掌握"长视频→短视频转化能力"的玩家有结构性优势,现在这种优势会被快速抹平。竞争的轴会重新回到"内容本身的强度"上。
Create 反而是被高估的那个
它的颠覆性是最为直观的,所以最容易被讨论。AI 生成图像、AI 生成视频、AI 写剧本、AI 作曲等等,这些话题在媒体上反复被讨论。
但真正会重新分配收益的,是那些没那么显眼的原语:协调、评估、验证、转换、翻译。它们决定了价值在产业链上往哪里流。
Create 这件事,最终的瓶颈不在"能不能生成",而在"生成的东西能不能打动人"。这个判断标准是高度主观的、文化绑定的、上下文依赖的。AI 在这件事上的进度会比技术指标显示的慢。
而那些"中间层"的原语,恰恰是那些 stakes 中等、可验证性中等、过去因为"协调成本太高"而难以规模化的工作。它们才是接下来三五年里,价值会被重新分配的地方。
结尾
Shapiro 在文章里没有给出预测,只是一个推演框架,我把它解读成两层意思。
第一层,GenAI 不是"又一次互联网"。互联网解决的是分发,GenAI 解决的是意义。前者重构了媒体的供应链,后者重构的是媒体的内容物本身。这两件事的尺度不一样。
第二层,对于做媒体、内容、产品以及战略的人来说,最有价值的工作不是去判断"AI 会不会取代我",而是去找出自己所从事的业务链条里那些"语义密度高、stakes 中等、可验证性中等"的环节。那些环节是接下来三五年里,价值会被重新分配的地方。
责任编辑:赵莹
24小时热文
流 • 视界










专栏文章更多
- [常话短说] 【大事】某广电押注小语种AI?! 2026-04-27
- [探显家] 从“分发”到“意义”:解读“三个信息时代”最新推演 2026-04-27
- [常话短说] 【解局】广电搞AI到底怎么发力? 2026-04-24
- [常话短说] 【重磅】广电一个大事发生了! 2026-04-23
- [常话短说] 【解局】某省联合发文,利好广电! 2026-04-22