




上文回顾:
AI技术干货|利用开源Transformer模型实现主要的NLP文本相关应用(上篇)
引言
基于开源大模型库快速实现AI应用系列教程将指导您如何利用开源大模型及其生态系统工具进行AI 应用的快速实现。我们将利用托管在诸如Hugging Face 等网站上的各种开源模型及其相关工具进行应用开发,这些工具包括Transformers、 Datasets、 Tokenizers及Accelerate等。
教程内容分为三大部分。首先,第一部分将深入探讨 Transformers库的核心概念。学习完这部分后,您不仅会对Transformer模型的运作有深入的了解,还能够熟练地使用各种开源模型,进行微调,实现AI 相关任务并分享您的成果。
接下来,我们将转向 Datasets和 Tokenizers的基础内容,并深入探讨各种NLP的经典任务。完成这部分学习后,您将能够独立处理各种常见的NLP问题。
最后一部分,我们将拓展到NLP之外,探索如何在语音处理和计算机视觉中应用Transformer模型。您将学习到如何为生产环境优化模型,构建并分享模型演示。当您完成这部分内容后,您将能够将 Transformers应用于几乎所有的机器学习问题。
为了更好地掌握本课程内容,您需要具备一些Python基础。如果您学习过实用深度学习编程或相关开发课程,那么学习本教程会更加得心应手。尽管要求您事先了解PyTorch或TensorFlow,但对它们有一定的了解会对您的学习大有裨益。
现在,让我们开始吧!在接下来的学习中,我们将探索如何使用pipeline()函数解决各种NLP任务,了解Transformer架构的基础,并区分编码器、解码器和编码器-解码器架构及其应用场景。由于篇幅的关系,本教程将采用连载的方式。
4基于Transformer的 NLP 应用
4.1 Transformer模型的应用
自从2017年由Vaswani等人在论文《Attention Is All You Need》中首次提出以来,Transformer架构已经在自然语言处理(NLP)领域引起了革命性的变化。其独特的自注意力机制和多头注意力设计使其在各种NLP任务中都表现出色。以下是Transformer模型的主要应用领域:
1. 机器翻译:Transformer模型最初是为机器翻译任务设计的,它在这方面的性能超越了之前的所有模型。通过捕获源语言和目标语言之间的复杂关系,Transformer能够生成流畅且准确的翻译。
2. 文本分类:无论是情感分析、主题分类还是意图识别,Transformer都已经成为了文本分类任务的首选模型。
3. 命名实体识别(NER):在这个任务中,Transformer可以识别文本中的特定实体,如人名、地点和组织名。
4. 问答系统:Transformer模型,特别是其变体如BERT,已被广泛应用于问答系统,能够从给定的文本段落中提取答案。
5. 文本生成:GPT系列模型,基于Transformer架构,已经展示了其在文本生成任务上的强大能力,从简单的句子生成到完整的文章撰写。
6. 文本摘要:Transformer模型可以用于自动文本摘要,生成原始文本的简短版本,同时保留其主要信息。
7. 语音识别和处理:尽管Transformer最初是为文本设计的,但它也被成功应用于语音任务,如语音识别和语音合成。
8. 多模态学习:Transformer模型也被用于处理图像和文本的联合任务,如图像描述和视觉问答。
9. 知识图谱:Transformer可以用于知识图谱的构建和查询,帮助机器理解和表示复杂的实体关系。
10. 零样本学习:基于Transformer的大型语言模型,如GPT-3,已经展示了在没有任何特定任务训练数据的情况下解决任务的能力。
Transformer模型的灵活性和强大的表示能力使其在NLP领域的各种任务中都取得了显著的成功。随着研究的深入和技术的进步,我们可以预期Transformer将继续扩展其应用范围,为自然语言处理和其他相关领域带来更多的创新。
在下面的小节,我们采用pipeline实现如下的NLP 任务,这些任务包括:
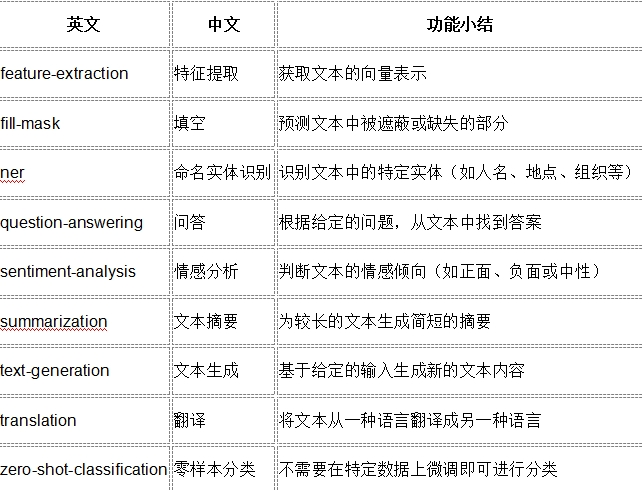
让我们看一些这些应用示例!
4.2 NLP零样本分类及其示例
零样本分类(zero-shot classification) 指的是机器学习模型在未在训练过程中见过的类别上进行分类的能力。在自然语言处理(NLP)的背景下,零样本分类尤为引人注目,因为它允许模型理解并将文本分类到在训练数据中未明确出现的主题或情感中。
4.2.1 关键概念
1. 跨类别的泛化:传统的监督学习要求模型在训练时对每个特定的类别进行训练,然后在后续进行预测。在零样本学习中,模型基于某种语义相似性或共享上下文从训练类别泛化到未见过的类别。
2. 语义嵌入:NLP中零样本分类成为可能的原因之一是由于嵌入提供的语义理解。像BERT或GPT-2这样的模型生成的嵌入在高维空间中捕获了单词和句子的含义。这种语义理解允许模型对未见过的类别进行推断。
3. 标签描述:对于零样本分类,通常会为模型提供每个类别的描述。这样,即使模型在训练过程中没有看到某个特定的类别标签,它也可以使用描述来理解并进行预测。
4.2.2 应用
· 主题分类:如果你有一组文档,并希望将它们分类到可能不是你初始训练集的部分的主题中,零样本分类会很有用。
· 情感分析:虽然模型可能在"正面"、"负面"和"中性"等基本情感上进行了训练,但零样本分类可以使其预测更为细致的情感,如"欣喜"或"绝望"。
· 意图识别:在聊天机器人或虚拟助手中,零样本分类可以帮助理解用户未明确训练的意图。
4.2.3 优势
1. 可扩展性:每当出现新的类别时,都不需要重新训练模型。
2. 灵活性:可以适应各种任务,而无需为每个潜在的类别提供详尽的标注数据。
4.2.4 局限性
1. 准确性:零样本分类可能不总是与传统的监督方法一样准确,特别是如果未见过的类别与训练类别非常不同的情况下。
2. 依赖高质量的嵌入:NLP中零样本分类的有效性在很大程度上依赖于嵌入的质量和模型的语义理解。
总之,NLP中的零样本分类为处理人类语言的不断发展提供了一个有前途的方向,允许模型对它们没有明确训练过的数据进行预测。
4.2.5 示例
我们首先来处理一个具挑战性的任务,即需要对没有标签的文本进行分类。在实际项目中,这是一个常见的场景,因为标注文本通常是耗时的,并需要领域专长。对于这种用例,zero-shot-classification pipeline非常强大:它允许你指定用于分类的标签,所以你不必依赖预训练模型的标签。你已经看到模型如何使用这两个标签(正面或负面)来分类一个句子——但它也可以使用你喜欢的任何其他标签集来分类文本。
from transformers import pipeline
# 初始化零样本分类器
classifier = pipeline(
"zero-shot-classification",
model="joeddav/xlm-roberta-large-xnli"
)
# 对给定的文本进行分类
result = classifier(
"这是一个关于Transformers库的课程",
candidate_labels=["教育", "政治", "商业"]
)
print(result)
输出结果
{
'sequence': '这是一个关于Transformers库的课程',
'labels': ['教育', '商业', '政治'],
'scores': [0.976, 0.011, 0.003]
}
4.2.5.1 代码解释
· 首先,我们从transformers库中导入了pipeline函数。
· 接着,我们初始化了一个名为classifier的零样本分类器。这里,我们指定了模型为joeddav/xlm-roberta-large-xnli,这是一个预训练的多语言模型,特别适用于零样本分类任务。
· 使用classifier,我们对给定的句子"这是一个关于Transformers库的课程"进行分类。我们提供了一个候选标签列表:["教育", "政治", "商业"],希望模型能够根据句子的内容为其分配正确的标签。
4.2.5.2结果解读
· 输出结果显示,给定的句子与"教育"这一标签的匹配度最高,得分为0.976,这意味着模型以约97.6%的置信度认为这句话与"教育"相关。
· 其次,句子与"商业"的匹配度为0.011,即1.1%的置信度。
· 最后,与"政治"的匹配度最低,仅为0.003,即0.3%的置信度。
综上所述,模型非常确信这句话与"教育"相关,而与其他两个标签的相关性较低。这也符合我们的直觉,因为句子确实是在描述一个关于Transformers库的课程,这与"教育"直接相关。
此外,这个pipeline被称为零样本,因为你不需要在你的数据上微调模型就可以使用它。它可以直接返回你想要的任何标签列表的概率分数,这为NLP任务提供了极大的便利性。
4.3 文本生成
文本生成是自然语言处理(NLP)中的一个关键任务,涉及自动产生连贯和有意义的文本。
4.3.1 定义
文本生成是指从某种输入(如图像、数字或短文本)生成自然语言文本的过程。这种生成可以是创造性的,如编写故事或诗歌,也可以是基于数据的,如生成天气报告或股票市场更新。
4.3.2 应用场景
· 机器翻译:将一种语言的文本转换为另一种语言。
· 自动摘要:从长篇文章中提取关键信息生成简短摘要。
· 对话系统和聊天机器人:生成与用户的自然对话。
· 创意写作:如生成诗歌、故事或歌词。
· 图像描述:为图像生成描述性文本。
· 代码生成:从自然语言描述生成代码。
4.3.3 技术和方法
· 循环神经网络 (RNN):是早期用于文本生成的主要神经网络结构,特别是LSTM和GRU。
· Transformer 架构:如GPT(Generative Pre-trained Transformer)和BERT(Bidirectional Encoder Representations from Transformers),它们利用自注意力机制处理序列数据,已成为文本生成的主流方法。
· 预训练与微调:先在大型文本数据集上预训练模型,然后在特定任务上进行微调,这种方法已被证明在文本生成任务上非常有效。
4.3.4 挑战
· 连贯性与一致性:生成的文本需要在整体上连贯和一致。
· 避免重复:长文本生成中常见的问题是内容的重复。
· 控制性:如何按照特定的指导或风格生成文本。
· 偏见与公正性:确保生成的文本不包含或放大任何形式的偏见。
4.3.5 示例
现在,让我们看看如何使用pipeline来生成一些文本。主要的思路是,你提供一个提示,模型会自动完成它,生成剩下的文本。这类似于许多手机上找到的预测文本功能。文本生成涉及到随机性,所以如果你得到的结果与下面显示的不同,这是正常的。
VIP专享文章,请登录或扫描以下二维码查看

“码”上成为VIP会员
没有多余的门路、套路
只有简单的“值来值往”一路!
深度分析、政策解读、研究报告一应俱全
极致性价比,全年精彩内容不容错过!
更多福利,尽在VIP专享
24小时热文
流 • 视界










专栏文章更多
- OTT月报|2025年4月智能电视大数据报告 2025-05-27
- IPTV月报|2025年4月家庭智慧屏IPTV报告 2025-05-27
- 见微知著|对话爆款制造机听花岛,短剧的“短”究竟是什么? 2025-05-19
- [常话短说] 【重要】5G能否救广电?! 2025-05-13
- IPTV月报|2025年3月家庭智慧屏IPTV报告 2025-05-08